Test sets
A test set is a collection of test cases with shared configuration. Each test set defines the conversation shape, which checks to apply, and how tools should behave during the evaluation.Creating a test set
- Click New test set in the Evals tab.
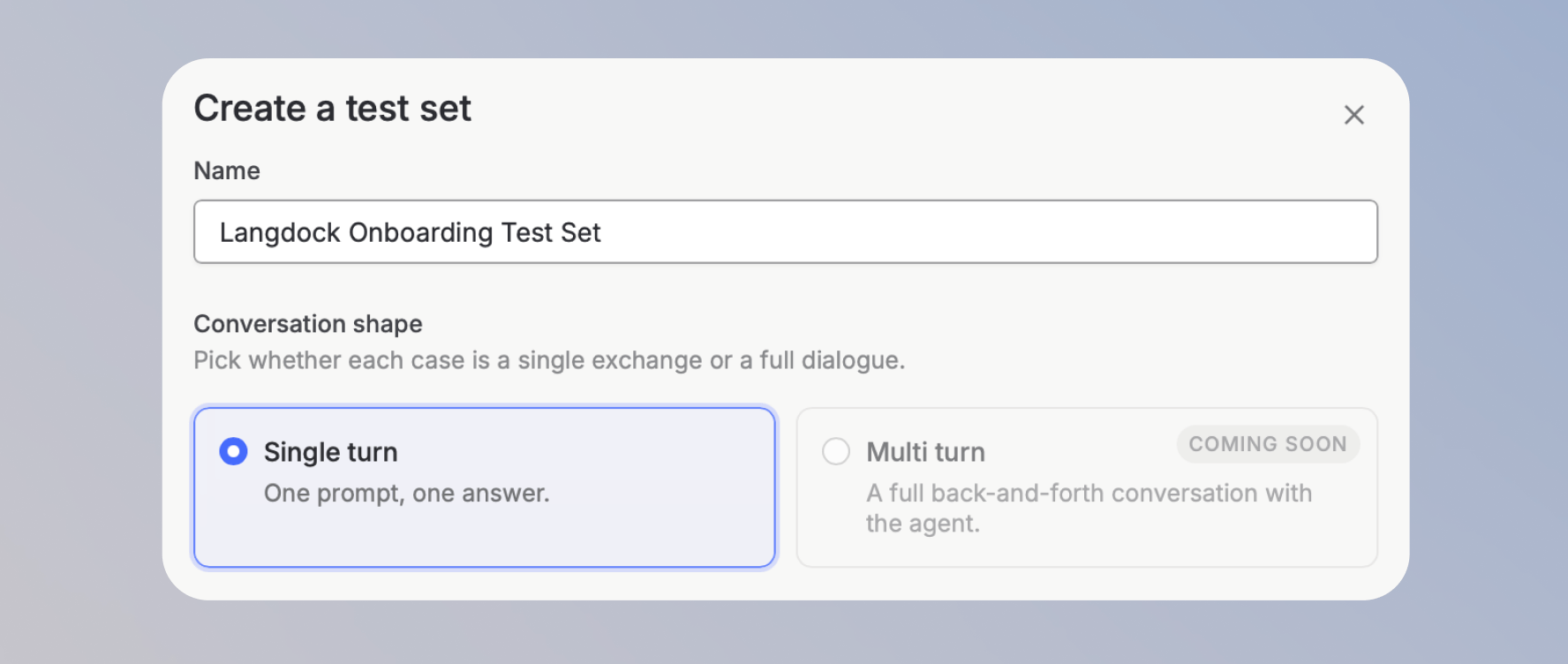
- Enter a name for the test set and select a conversation shape. Currently, only Single turn is available.
- Optionally, select one or more checks to grade your test cases: AI judge, Tool check, or Keyword check.

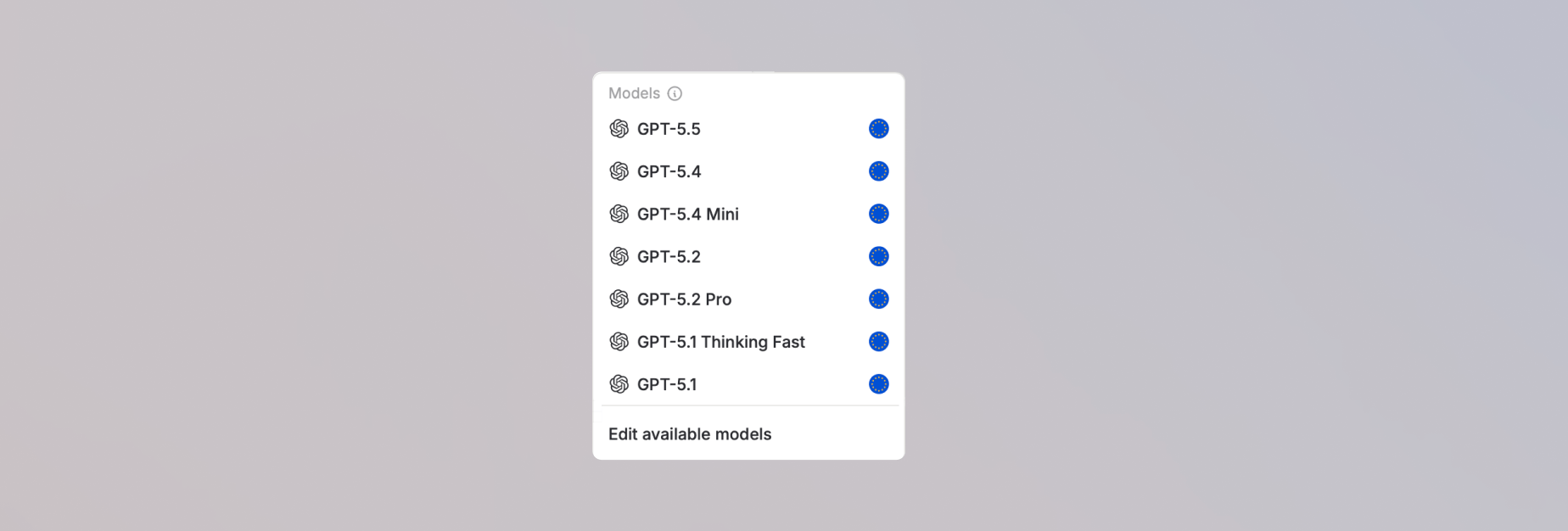
- If you selected AI judge, choose which model to use as the judge.
- Click Create test set.
Check types
Checks define how each test case is graded. You select them when creating a test set, and they apply to every case in that set.AI judge
AI judge compares your agent’s actual response to an expected answer you define for each test case. It uses a language model to evaluate whether the response meets the intent and content of the expected answer, even if the wording differs. You choose which model serves as the judge when creating the test set.Tool check
Tool check verifies whether your agent called the expected tools for a given prompt. Define the tools you expect to be used, and the check confirms whether the agent called them during the evaluation. This is useful for agents with integration actions where calling the correct tool matters as much as the response itself.Keyword check
Keyword check verifies whether the agent’s response contains required words or avoids forbidden words. Unlike AI judge, it does not involve a model and produces a deterministic pass or fail result. Each test case has two fields for this check: Must mention and Must not mention. Use it for compliance requirements, brand guidelines, or any case where certain terms must appear or must be avoided in the response.Test cases
After creating a test set, you add the individual test cases that will be evaluated.Adding cases manually
Click Add case on the test set page to create a single test case. Each case includes a prompt and the expected outputs that your selected checks will grade against.
Importing from CSV
For larger test sets, click Import CSV to load multiple cases at once. The CSV requires aprompt column. It can also include must_contain, must_not_contain, reference_answer, and expected_tools columns.
Importing from CSV is the fastest way to build comprehensive test sets, especially if you already maintain a spreadsheet of prompts you use for manual testing.
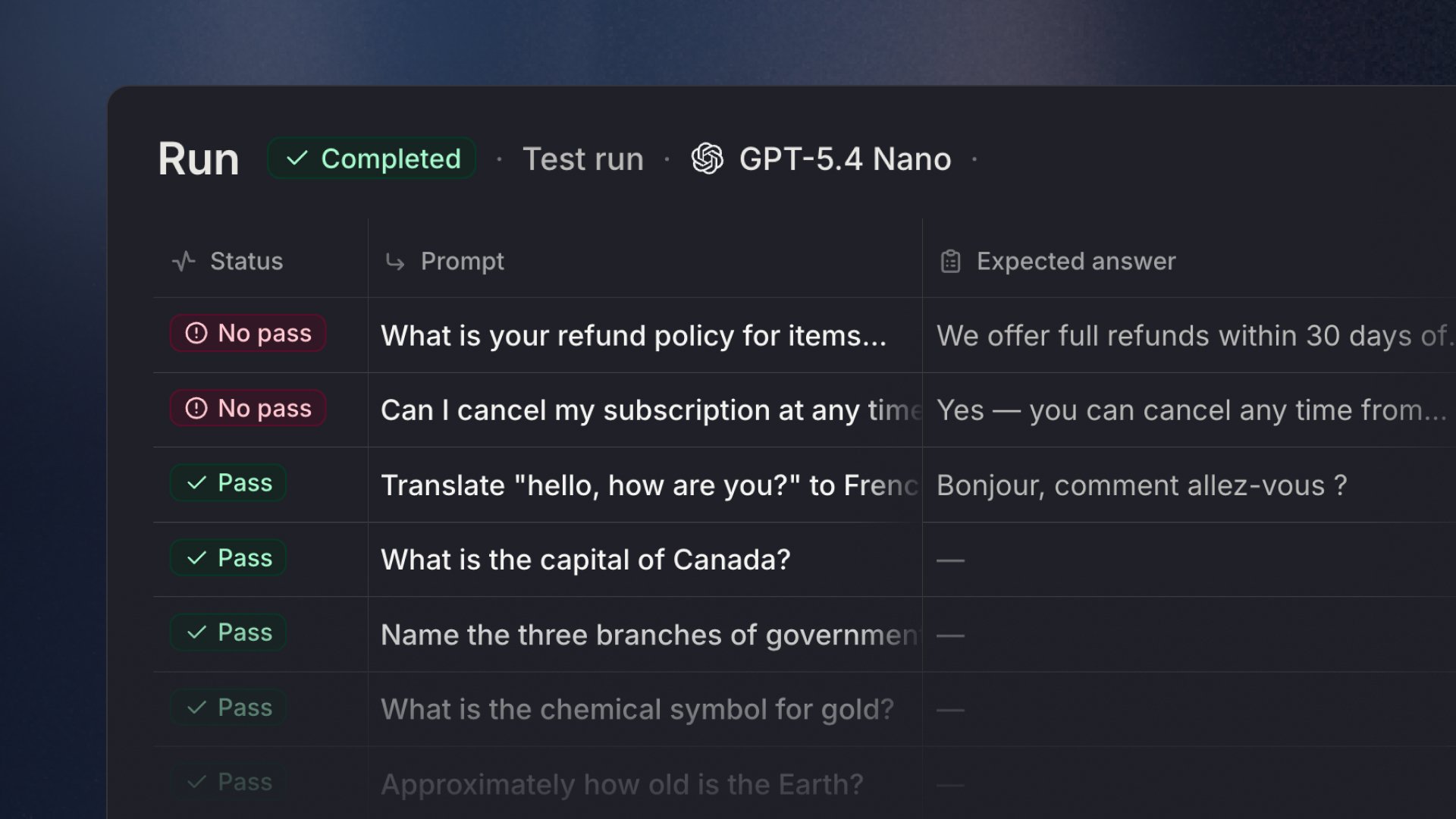
Running evals
Click Run in the top right of the test set page to start the evaluation. Results appear live as each case completes, showing the status, prompt, output, grader results, and duration for each case.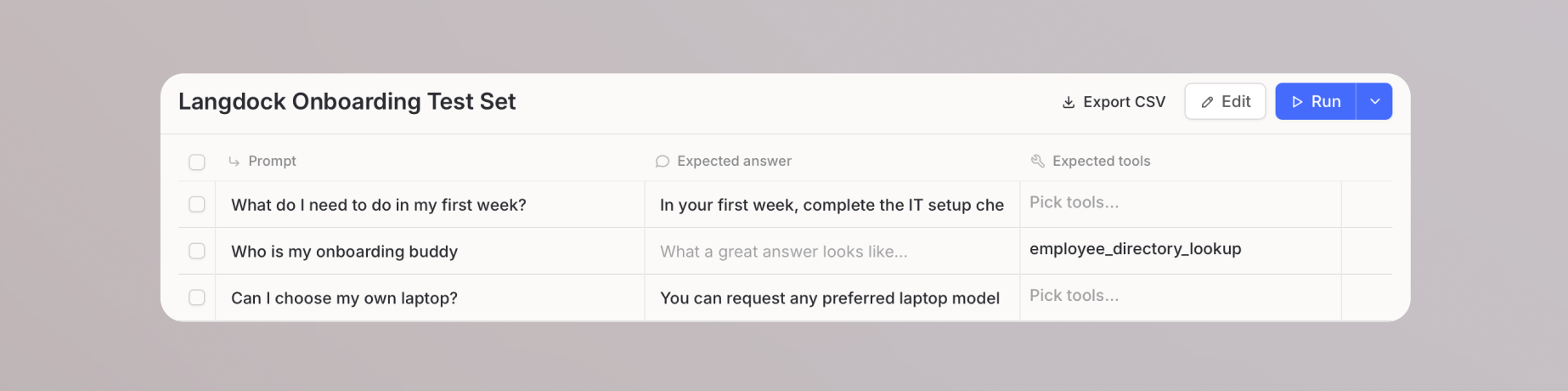
Each test case consumes usage in the same way as a regular agent conversation. A test set can only have one active run at a time, and each workspace can have up to three active runs.
Reviewing results
Once a case finishes, click on it to open the detail view. You can review: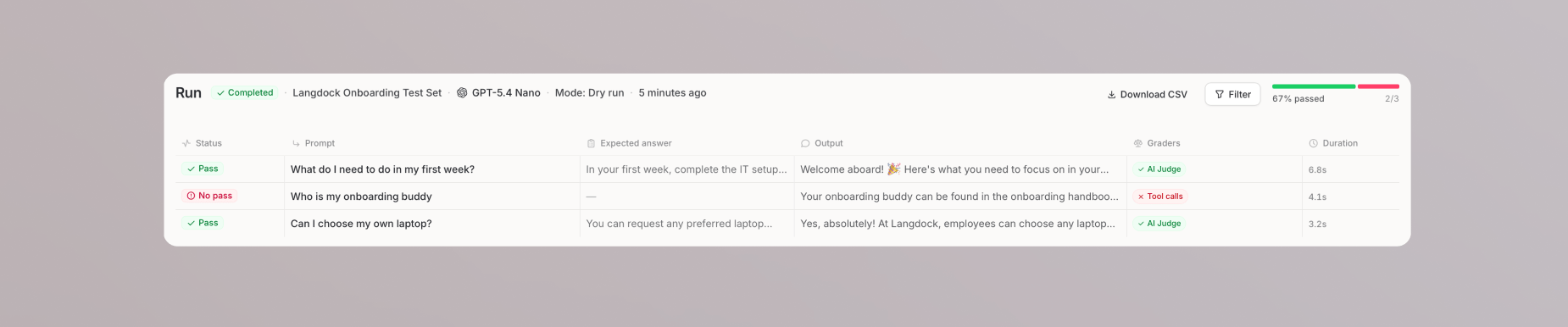
- The full conversation between the prompt and the agent
- The agent’s response
- Token usage and duration
- The result of each grader, such as pass, no pass, or unsure