Wähle deinen Anbieter aus, um die Einrichtungsschritte zu sehen.Documentation Index
Fetch the complete documentation index at: https://docs.langdock.com/llms.txt
Use this file to discover all available pages before exploring further.
Google Vertex AI / AI Studio
Google Vertex AI / AI Studio
Langdock unterstützt zwei Wege, Gemini-Modelle zu verbinden: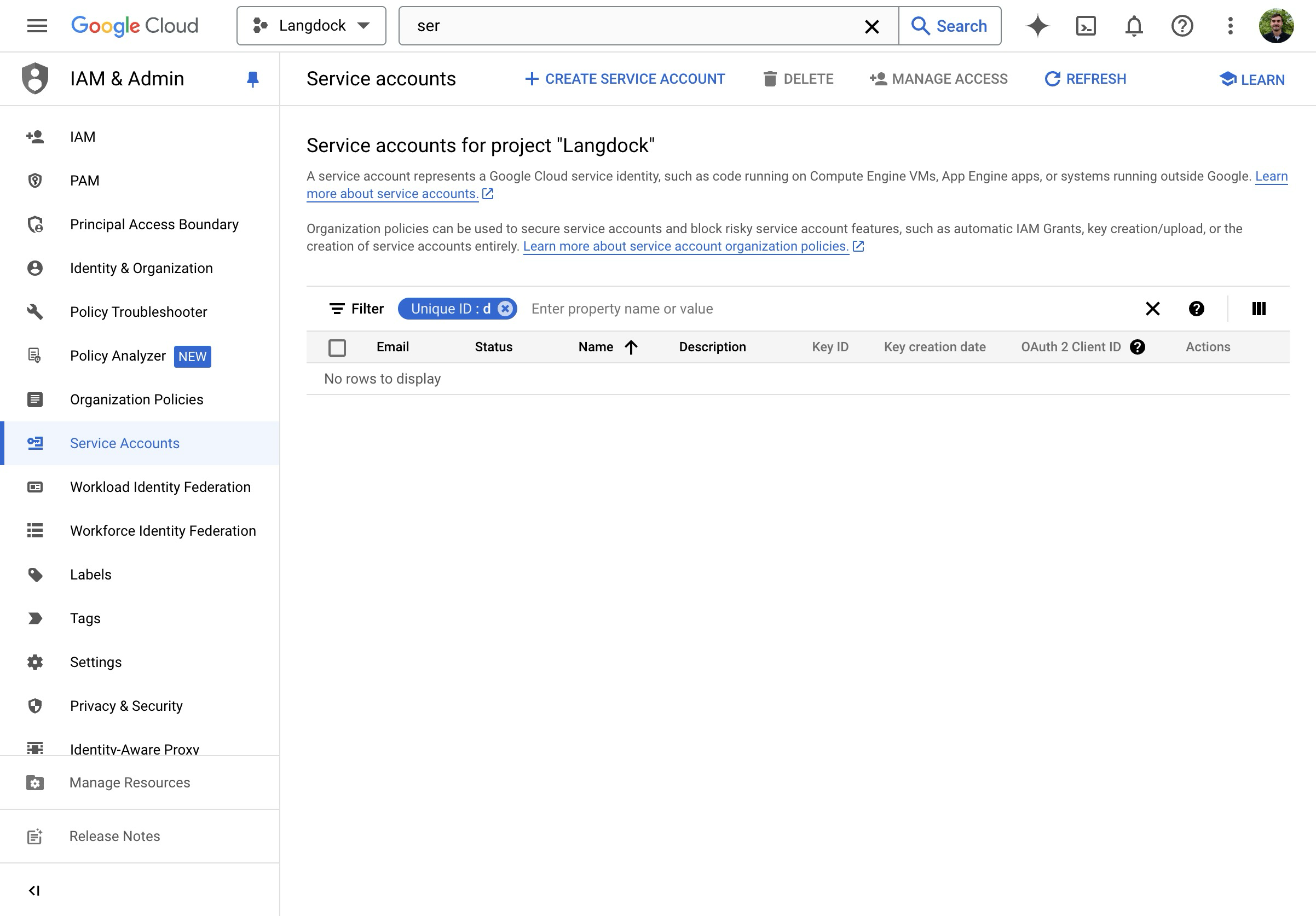
- Google Vertex AI: verwendet Service-Account-Zugangsdaten. Am besten für Enterprise-Setups mit GCP-Infrastruktur.
- Google AI Studio: verwendet einen einfachen API-Schlüssel. Einfacher einzurichten.
Option 1: Google Vertex AI
Google Cloud einrichten
- Aktiviere die Vertex AI API in deiner Google Cloud Platform.
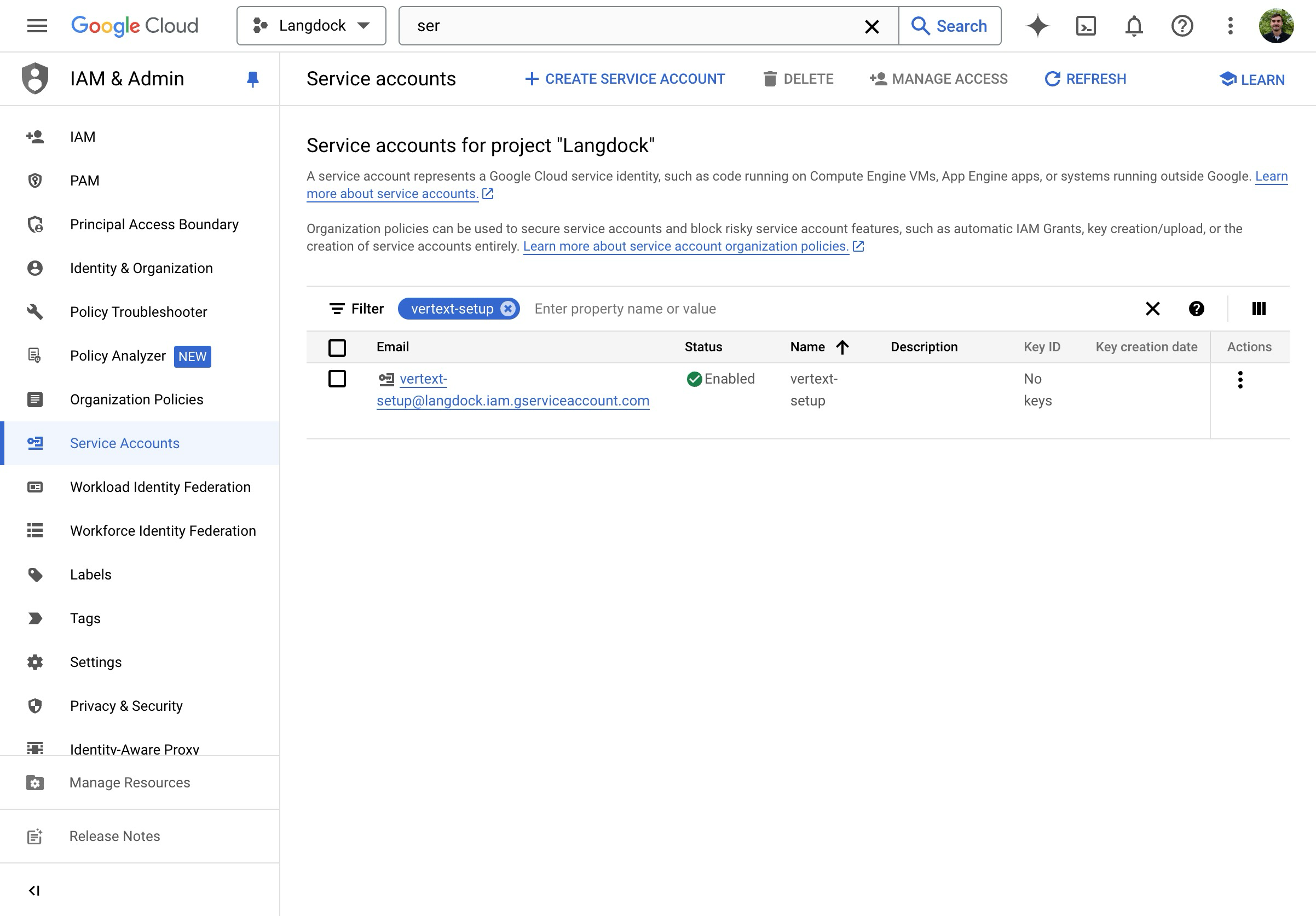
- Gehe zu “Service Accounts” in den Google Cloud Console IAM-Einstellungen.
- Klicke auf “Create Service Account”.
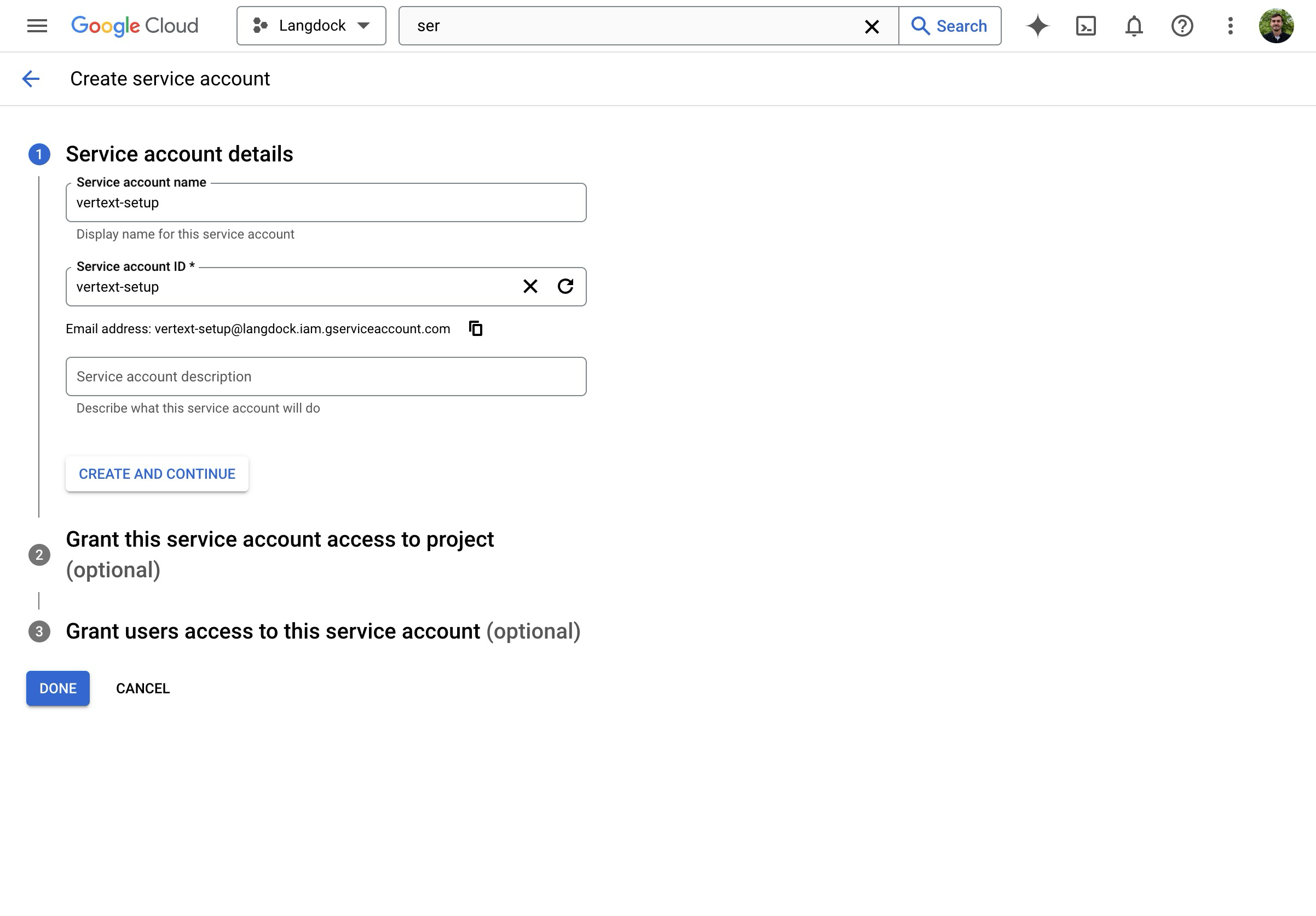
- Gib dem Service Account einen Namen.
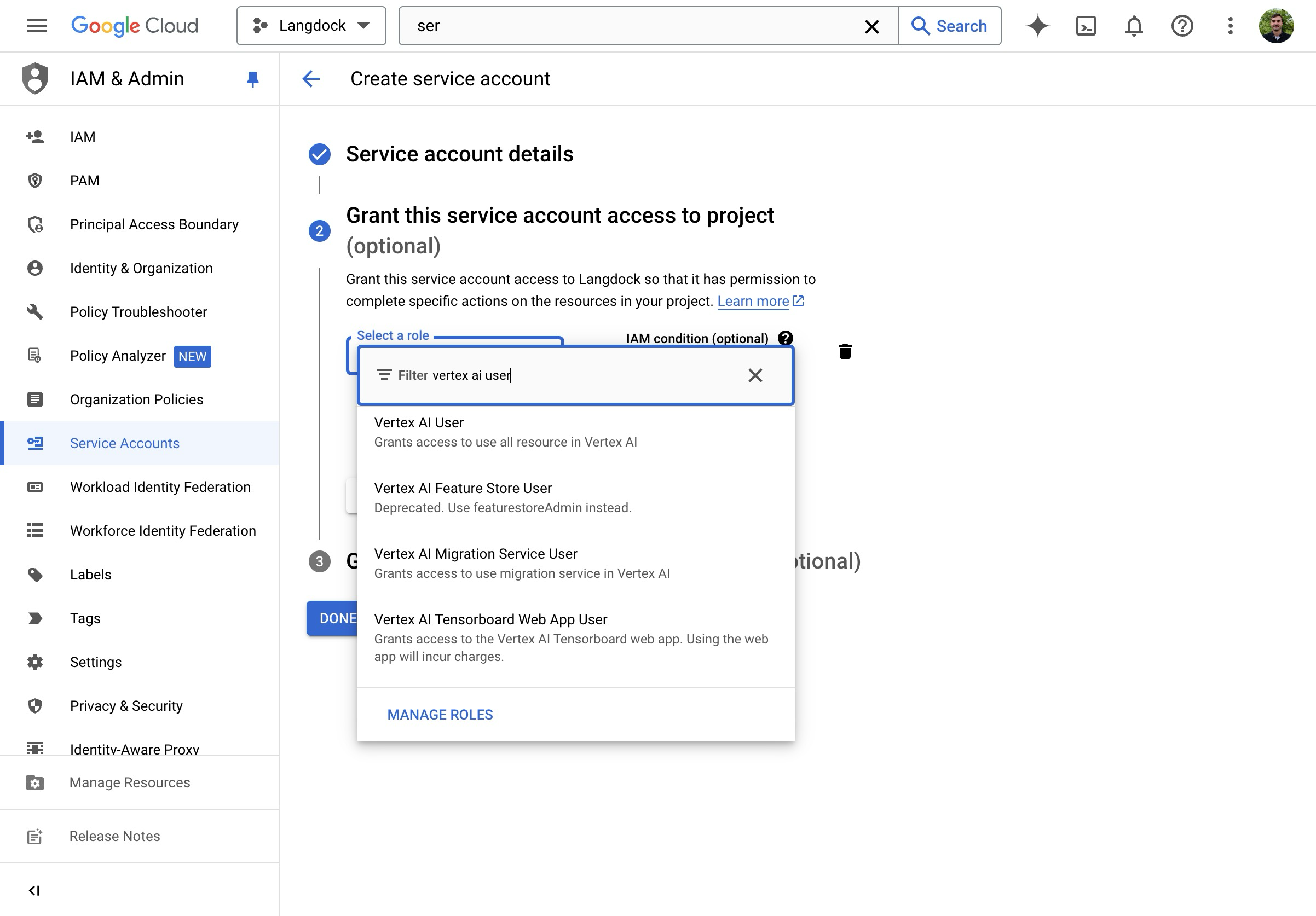
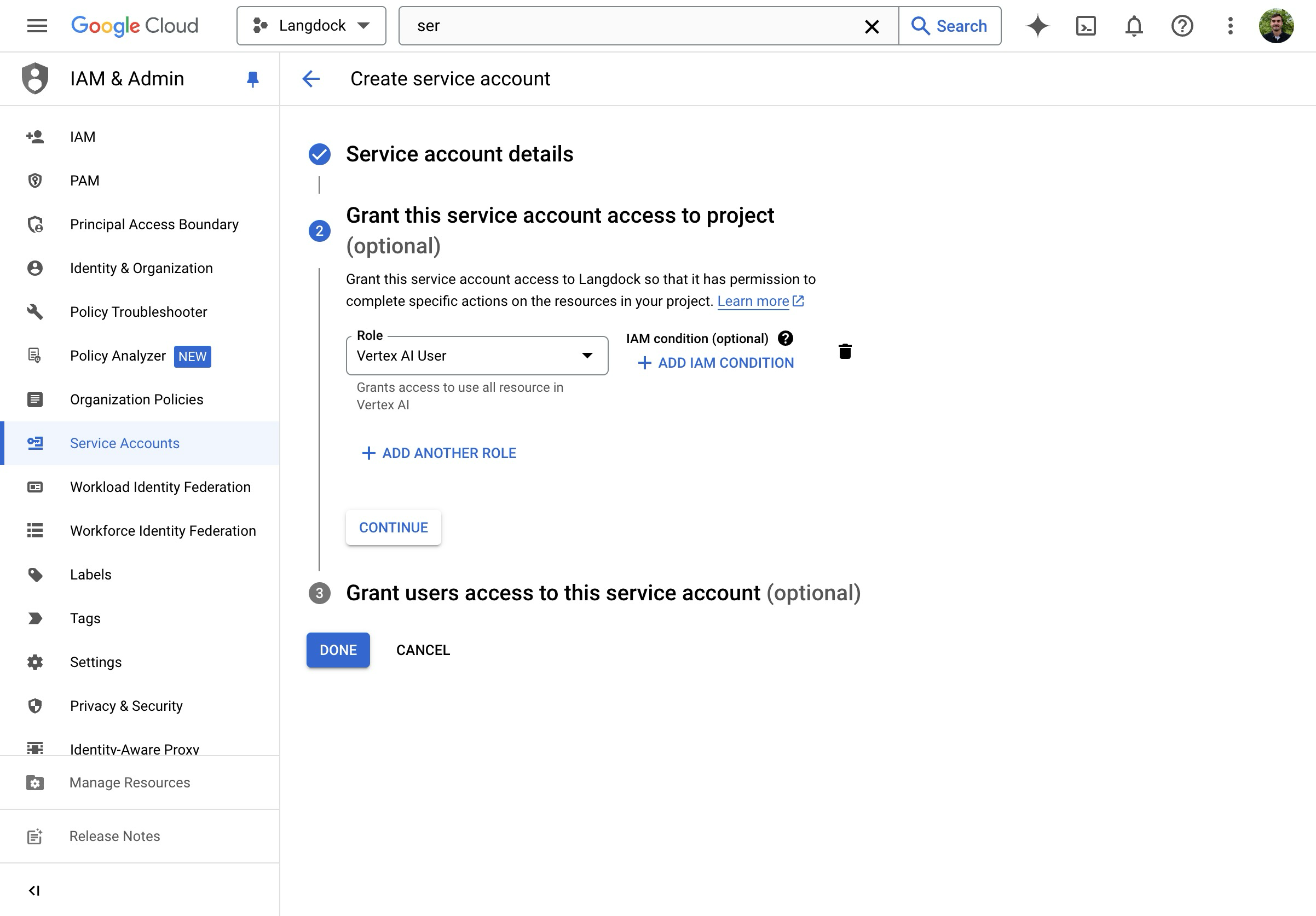
- Weise die Rolle “Vertex AI User” zu.
- Erstelle den Service Account.
- Du gelangst zurück zur Service Account Übersicht.
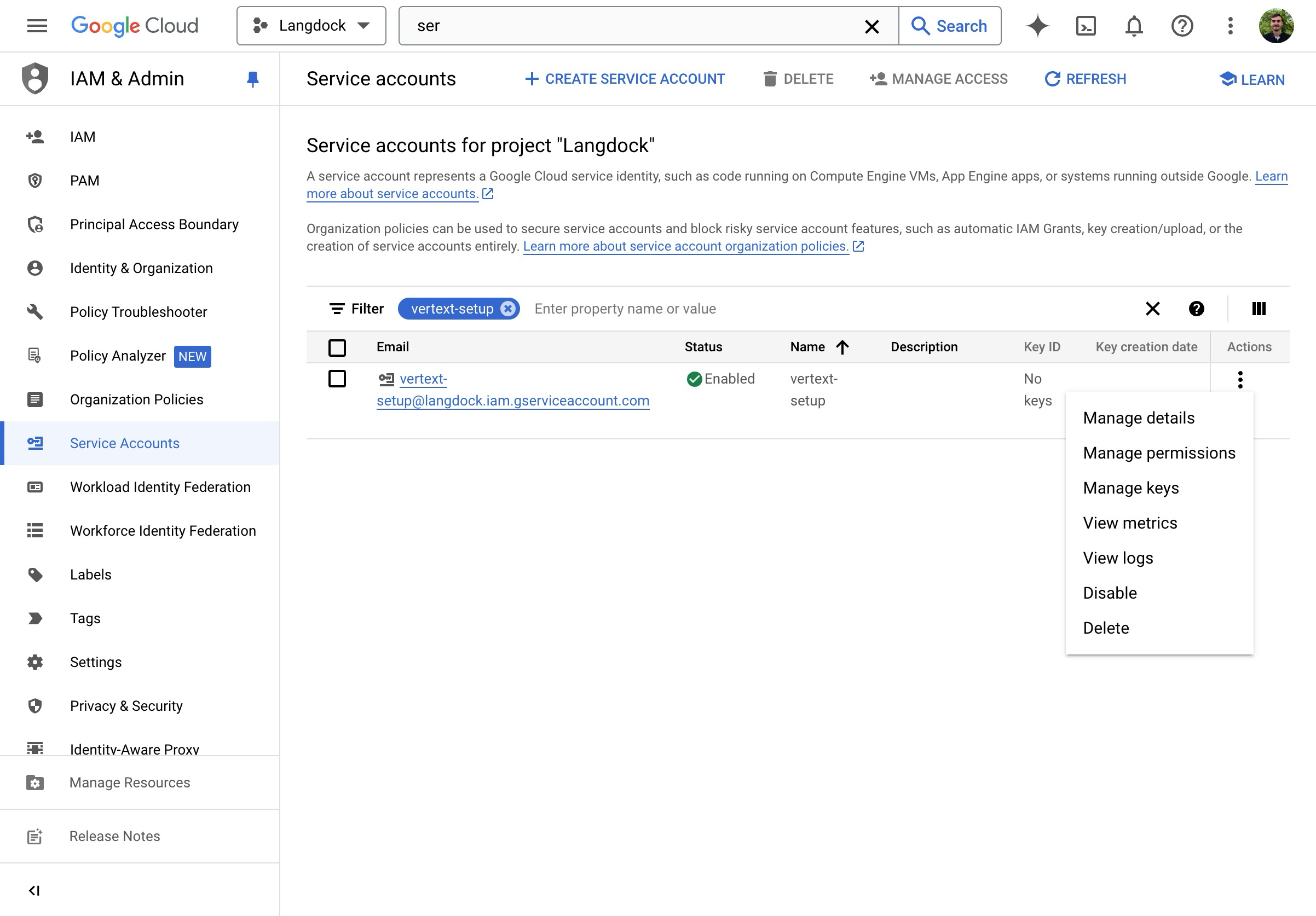
- Klicke auf der Übersichtsseite auf “Manage keys”.
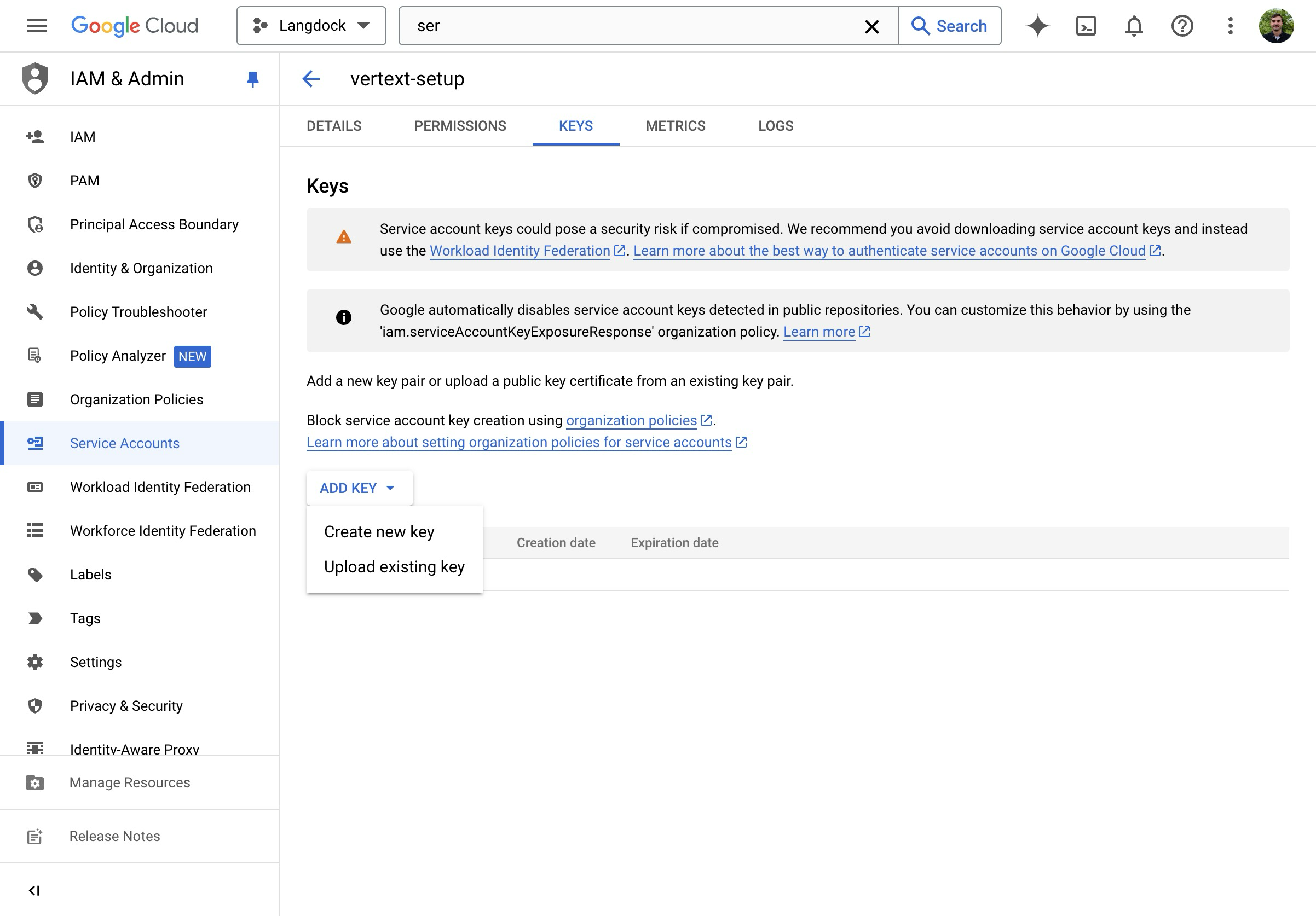
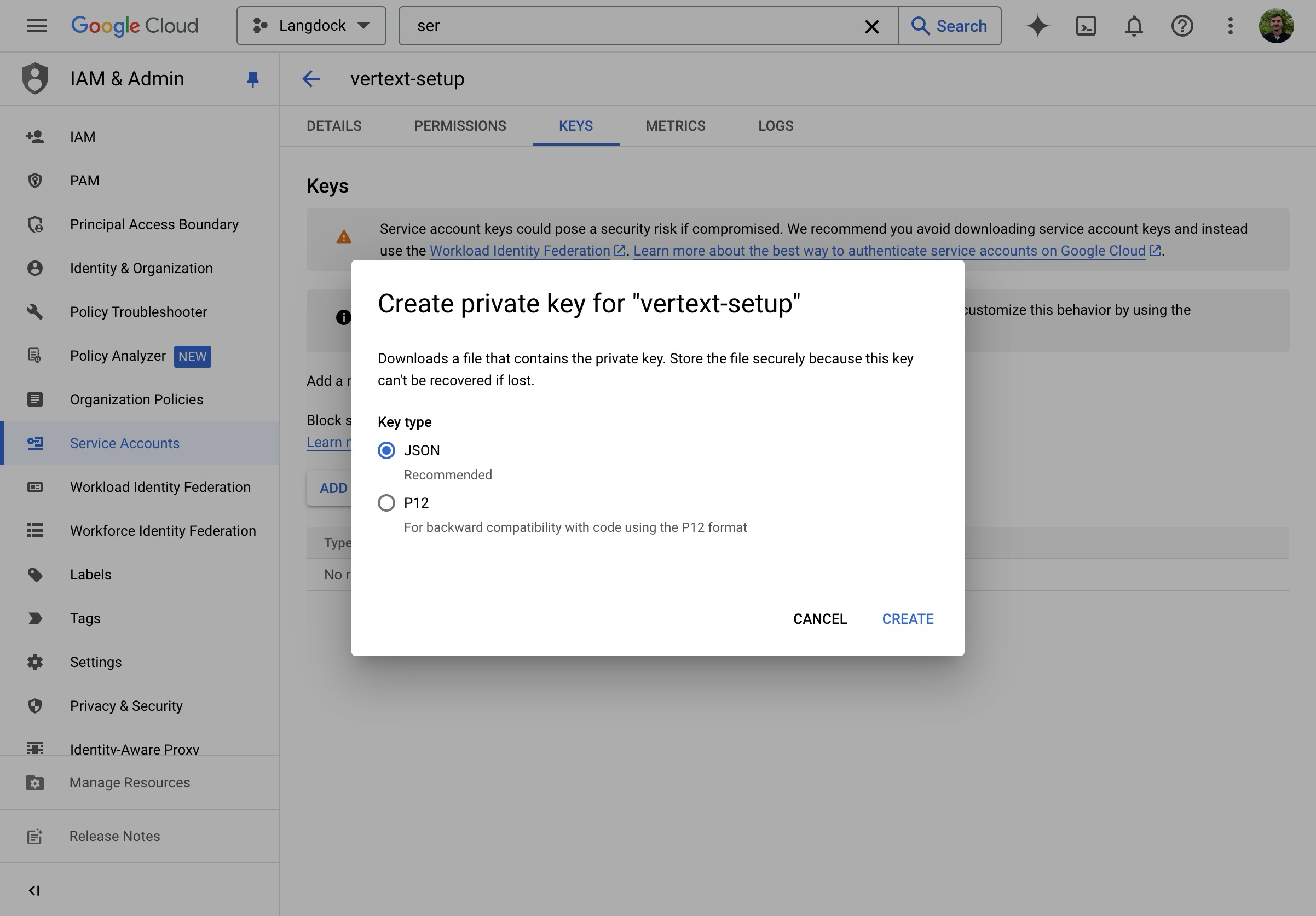
- Erstelle einen neuen JSON-Schlüssel.
- Lade die JSON-Datei herunter und öffne sie.
Langdock einrichten
- Navigiere zu Workspace-Einstellungen -> Modelle und klicke auf Eigenes Modell hinzufügen.
- Nutze die vorgefertigte Langdock-Konfiguration oder richte es manuell ein. Setze das SDK auf Google Vertex.
Wenn du das Google Vertex SDK auswählst, beschriftet die Oberfläche die Felder um: “Base URL” wird zu Service Account Email und “API Key” wird zu Service Account Private Key.
-
Fülle die Verbindungsfelder aus:
- Service Account Email: füge den
client_email-Wert aus deiner JSON-Schlüsseldatei ein (z.B.my-sa@my-project.iam.gserviceaccount.com) - Service Account Private Key: füge den
private_key-Wert aus deiner JSON-Schlüsseldatei ein (einschließlich-----BEGIN PRIVATE KEY-----und-----END PRIVATE KEY-----) - Region: deine Vertex AI Region (z.B.
europe-west3,us-central1). Diese bestimmt, welcher Vertex AI Endpunkt verwendet wird. - Model ID: die Modell-ID aus dem Vertex Portal (z.B.
gemini-2.5-flash,gemini-2.5-pro)
- Service Account Email: füge den
- Klicke auf Testen & weiter und nach erfolgreichem Test auf Modell speichern.
Die GCP-Projekt-ID wird automatisch aus deiner Service Account Email extrahiert. Du musst sie nicht separat eingeben.
Option 2: Google AI Studio
- Hole dir einen API-Schlüssel von Google AI Studio.
- Navigiere zu Workspace-Einstellungen -> Modelle und klicke auf Eigenes Modell hinzufügen. Wähle Google AI Studio als SDK.
- Füge deinen API-Schlüssel ein und setze die Model ID.
- Klicke auf Testen & weiter und nach erfolgreichem Test auf Modell speichern.
Imagen (Bildgenerierung)
Folge der Vertex AI-Einrichtung oben, setze aber den Modelltyp auf Image Generation und verwende eine Imagen Model ID (z.B.imagen-4.0-generate-001).AWS Bedrock
AWS Bedrock
AWS Bedrock gibt dir Zugang zu Modellen wie Claude über deine eigene AWS-Infrastruktur mit Enterprise-Sicherheit und Compliance.Voraussetzungen:
Beispiel:
- Ein AWS-Konto mit aktiviertem Bedrock-Zugang
- IAM-Zugangsdaten mit Bedrock-Berechtigungen
- Modellzugang in deiner AWS Bedrock Konsole aktiviert
- Admin-Zugang zu deinem Langdock Workspace
AWS einrichten
1. Modellzugang aktivieren
- Gehe zur AWS Bedrock Konsole.
- Navigiere zu Model access in der linken Seitenleiste.
- Klicke auf Manage model access und aktiviere die benötigten Modelle.
- Warte, bis der Zugang gewährt wurde (kann einige Minuten dauern).
2. IAM-Zugangsdaten erstellen
- Gehe zur AWS IAM Konsole.
- Navigiere zu Users und klicke auf Create user.
- Gib dem Nutzer einen beschreibenden Namen (z.B.
langdock-bedrock-access). - Füge die
AmazonBedrockFullAccess-Richtlinie hinzu oder erstelle eine benutzerdefinierte Richtlinie mit den Mindestberechtigungen:
- Gehe zum Tab Security credentials des Nutzers, klicke auf Create access key, wähle Third-party service und speichere sowohl die Access Key ID als auch den Secret Access Key.
Langdock einrichten
- Navigiere zu Workspace-Einstellungen -> Modelle und klicke auf Eigenes Modell hinzufügen.
- Wähle Bedrock als SDK.
-
Fülle die Verbindungsfelder aus:
- Access Key ID: deine AWS Access Key ID
- Secret Access Key: dein AWS Secret Access Key
- Region: deine AWS Region (z.B.
us-east-1,eu-central-1) - Model ID: verwende den Bedrock Modell-Identifier (siehe unten)
- Context Size: entsprechend dem Modell einstellen (siehe Modellkonfigurationstabellen)
- Klicke auf Testen & weiter und nach erfolgreichem Test auf Modell speichern.
Model IDs
| Anbieter | Format | Beispiel |
|---|---|---|
| Anthropic | anthropic.{model-name} | anthropic.claude-sonnet-4-6 |
| Meta | meta.{model-name}-v1:0 | meta.llama4-maverick-17b-instruct-v1:0 |
| Amazon | amazon.{model-name}-v1:0 | amazon.nova-pro-v1:0 |
Schau auf der AWS Bedrock Seite für unterstützte Modelle für genaue Model IDs.
Cross-Region Inference Profiles
Stelle der Model ID einen geografischen Code voran, um automatisch über Regionen zu routen:| Präfix | Geltungsbereich |
|---|---|
us. | US-Regionen |
eu. | Europäische Regionen |
global. | Alle kommerziellen Regionen |
apac. | Asien-Pazifik Regionen |
eu.anthropic.claude-sonnet-4-6Schau in die Inference Profiles Dokumentation für verfügbare Profile je Modell.Unterstützte Regionen
- US East (N. Virginia):
us-east-1 - US West (Oregon):
us-west-2 - EU (Frankfurt):
eu-central-1 - EU (Irland):
eu-west-1 - EU (Paris):
eu-west-3 - Asien-Pazifik (Tokio):
ap-northeast-1 - Asien-Pazifik (Sydney):
ap-southeast-2
Netzwerkkonfiguration
Wenn deine Organisation Network Allowlisting verwendet, fügebedrock.REGION.amazonaws.com zu deiner Allowlist hinzu (ersetze REGION durch deine AWS Region, z.B. us-east-1).Fehlerbehebung
“Access Denied”-Fehler: überprüfe die IAM-Berechtigungen und dass der Modellzugang in der Bedrock Konsole aktiviert ist.Modell nicht verfügbar: bestätige, dass das Modell in deinen AWS Bedrock Modellzugriffseinstellungen aktiviert und in deiner ausgewählten Region verfügbar ist.Authentifizierungsfehler: überprüfe, dass Access Key ID und Secret Access Key korrekt sind und die Region-Einstellung deiner Bedrock-Region entspricht.Langsame Antworten oder Timeouts: erwäge die Nutzung einer Region näher bei deinen Nutzern. Prüfe das AWS Service Health Dashboard auf laufende Probleme. Stelle sicher, dass dein AWS-Konto ausreichende Kontingente für das Modell hat.Mistral
Mistral
Mistral-Modelle verbinden sich über die Mistral API oder über Azure (für Azure-gehostetes Mistral).Voraussetzungen:
- Ein Mistral-Konto bei console.mistral.ai
- Ein API-Schlüssel von der Mistral-Plattform
- Admin-Zugang zu deinem Langdock Workspace
Einrichtung
- Navigiere zu Workspace-Einstellungen -> Modelle und klicke auf Eigenes Modell hinzufügen.
-
Fülle die Verbindungsfelder aus:
- SDK: wähle Mistral
- Base URL: leer lassen für den Standard (
https://api.mistral.ai/v1) oder einen benutzerdefinierten Endpunkt angeben - Model ID: verwende den offiziellen Modell-Identifier (siehe unten)
- API Key: füge deinen Mistral API-Schlüssel ein
- Klicke auf Testen & weiter und nach erfolgreichem Test auf Modell speichern.
Model IDs
| Model ID | Anwendungsfall |
|---|---|
mistral-large-latest | Flagship-Modell — komplexes Reasoning, mehrsprachig, Instruktionsfolgen |
codestral-latest | Code-spezialisiert — Code-Generierung und technische Aufgaben |
mistral-small-latest | Schnell und kosteneffizient — gut für alltägliche Aufgaben |
Schau in Mistrals Modelldokumentation für die vollständige Liste der verfügbaren Modelle.
Mistral über Azure verwenden
Wenn du Mistral-Modelle über Azure (via Azure AI Models-as-a-Service) verwendest, musst du trotzdem “Mistral” als SDK in Langdock auswählen. Die SDK-Auswahl bezieht sich auf das API-Format, nicht den Hosting-Anbieter.Konfigurationshinweise
- Mistral-Modelle unterstützen Tool Calling nativ.
- Der Standard-API-Endpunkt
https://api.mistral.ai/v1wird automatisch verwendet, wenn keine benutzerdefinierte Base URL angegeben wird. - Mistral-Modelle sind bekannt für starke mehrsprachige Fähigkeiten, besonders in europäischen Sprachen.
Fehlerbehebung
Modell antwortet nicht: überprüfe, ob dein API-Schlüssel gültig ist und du ausreichend Credits in deinem Mistral-Konto hast. Stelle sicher, dass die Model ID exakt übereinstimmt (Groß-/Kleinschreibung beachten).Authentifizierungsfehler mit Azure: überprüfe, dass du “Mistral” als SDK verwendest. Verifiziere, dass deine Azure-Endpunkt-URL und dein API-Schlüssel korrekt sind.Langsame Antworten: größere Modelle benötigen möglicherweise mehr Zeit für komplexe Reasoning-Aufgaben. Erwäge ein kleineres Modell für schnellere Antworten bei einfacheren Aufgaben.DeepSeek
DeepSeek
DeepSeek-Modelle verbinden sich über die DeepSeek API. Alle Modelle werden in der US-Region gehostet.Voraussetzungen:
- Ein DeepSeek-Konto bei platform.deepseek.com
- Ein API-Schlüssel von der DeepSeek-Plattform
- Admin-Zugang zu deinem Langdock Workspace
Einrichtung
- Navigiere zu Workspace-Einstellungen -> Modelle und klicke auf Eigenes Modell hinzufügen.
-
Fülle die Verbindungsfelder aus:
- SDK: wähle DeepSeek
- Base URL:
https://api.deepseek.com/v1 - Model ID: siehe Tabelle unten
- API Key: füge deinen DeepSeek API-Schlüssel ein
- Region: US
- Für Reasoning-Modelle (R1), aktiviere Always show reasoning, um den Denkprozess des Modells in der UI anzuzeigen.
- Klicke auf Testen & weiter und nach erfolgreichem Test auf Modell speichern.
Model IDs
| Model ID | Typ |
|---|---|
deepseek-reasoner | Reasoning-Modell (R1-Serie) — hervorragend für schrittweises Problemlösen und Coding |
deepseek-chat | Allzweck-Modell (V3-Serie) — schnelle Antworten, gut für alltägliche Aufgaben |
Schau in DeepSeeks API-Dokumentation für die neuesten verfügbaren Modelle.
Konfigurationshinweise
- DeepSeek-Modelle werden nur in der US-Region gehostet. DeepSeek-Modelle unterstützen keine Bildanalyse.
- DeepSeek R1 ist ein Reasoning-Modell. Aktiviere Always show reasoning, um seine Reasoning-Schritte in der UI zu sehen.
- Die Base URL muss den
/v1-Pfad enthalten:https://api.deepseek.com/v1.
Fehlerbehebung
Modell antwortet nicht: überprüfe, ob dein API-Schlüssel gültig ist und du ausreichend Credits hast. Stelle sicher, dass die Model ID exakt übereinstimmt (Groß-/Kleinschreibung beachten).Langsame Antworten: DeepSeek R1 (Reasoning-Modell) benötigt aufgrund seines schrittweisen Reasoning-Prozesses möglicherweise mehr Zeit. Verwende DeepSeek V3 für schnellere Antworten bei einfacheren Aufgaben.Perplexity
Perplexity
Perplexitys Sonar-Modelle kombinieren LLM-Fähigkeiten mit Echtzeit-Websuche. Alle Modelle werden in der US-Region gehostet.Voraussetzungen:
- Ein Perplexity-Konto bei perplexity.ai
- Ein API-Schlüssel aus deinen Perplexity API-Einstellungen
- Admin-Zugang zu deinem Langdock Workspace
Einrichtung
- Navigiere zu Workspace-Einstellungen -> Modelle und klicke auf Eigenes Modell hinzufügen.
-
Fülle die Verbindungsfelder aus:
- SDK: wähle Perplexity
- Base URL: leer lassen für den Standard (
https://api.perplexity.ai) - Model ID: siehe Tabelle unten
- API Key: füge deinen Perplexity API-Schlüssel ein
- Region: US
- Klicke auf Testen & weiter und nach erfolgreichem Test auf Modell speichern.
Model IDs
| Model ID | Typ |
|---|---|
sonar-pro | Erweiterte suchbasierte Generierung mit detaillierten Zitaten |
sonar | Schnelle suchbasierte Antworten für allgemeine Anfragen |
sonar-reasoning-pro | Tiefgehende Analyse mit Suche und mehrstufigem Reasoning |
sonar-reasoning | Reasoning mit Suchunterstützung |
Schau in Perplexitys Modelldokumentation für die vollständige Liste der verfügbaren Modelle.
Konfigurationshinweise
- Perplexity-Modelle haben eingebaute Websuchfähigkeiten und haben immer Zugang zu aktuellen Informationen.
- Der API-Endpunkt
https://api.perplexity.aiwird automatisch verwendet, wenn keine benutzerdefinierte Base URL angegeben wird. - Sonar Pro-Modelle liefern detailliertere Antworten mit besseren Quellzitaten.
- Reasoning-Varianten eignen sich am besten für komplexe analytische Aufgaben, die von schrittweisem Denken profitieren.
- Perplexity-Modelle unterstützen keine Bildanalyse.
Fehlerbehebung
Fehlende Zitate: Perplexity-Modelle fügen Zitate automatisch hinzu, wenn eine Websuche durchgeführt wird. Fehlen Zitate, hat das Modell aus seinem Basiswissen geantwortet.Langsame Antworten: Perplexity-Modelle führen Websuchen durch, was Latenz hinzufügt. Sonar (non-Pro) Varianten sind schneller als Pro-Versionen. Für zeitkritische Aufgaben ohne Suchbedarf erwäge ein anderes Modell.Modell antwortet nicht: überprüfe, ob dein API-Schlüssel gültig ist und du ausreichend Credits hast.OpenAI-kompatible Endpunkte
OpenAI-kompatible Endpunkte
Verwende dies für jede API, die der OpenAI-Spezifikation folgt, einschließlich vLLM, LiteLLM, Ollama und selbst gehosteter Modelle.Viele LLM-Inference-Lösungen implementieren die OpenAI API-Spezifikation als Standard-Interface. Das bedeutet, sie akzeptieren Anfragen und geben Antworten im gleichen Format wie OpenAIs API zurück, wodurch sie aus Integrationsperspektive austauschbar sind.Gängige OpenAI-kompatible Lösungen:
- vLLM: Hochdurchsatz-Inferenzserver für Large Language Models
- LiteLLM: Proxy-Server mit einheitlichem Interface für 100+ LLM-Anbieter
- Ollama: Large Language Models lokal ausführen
- Text Generation Inference (TGI): Hugging Faces Inferenzserver
- LocalAI: selbst gehostete, OpenAI-kompatible API
- Benutzerdefinierte Deployments: jeder Service, der die OpenAI Chat Completions API implementiert
- Ein laufender OpenAI-kompatibler Inferenz-Endpunkt, erreichbar über HTTPS
- Die Base URL deines Endpunkts
- Die Model ID/Name, wie in deinem Inferenzserver konfiguriert
- Ein API-Schlüssel (falls dein Endpunkt Authentifizierung erfordert)
- Admin-Zugang zu deinem Langdock Workspace
Einrichtung
- Navigiere zu Workspace-Einstellungen -> Modelle und klicke auf Eigenes Modell hinzufügen.
-
Fülle die Verbindungsfelder aus:
- SDK: wähle OpenAI Compatible
- Base URL: deine Endpunkt-URL (z.B.
https://your-server.com/v1). Pflichtfeld. - Model ID: der genaue Modell-Identifier, wie in deinem Inferenzserver konfiguriert
- API Key: dein Authentifizierungsschlüssel, oder leer lassen wenn nicht erforderlich
- Context Size: die Kontextfenstergröße deines Modells in Token
- Klicke auf Testen & weiter und nach erfolgreichem Test auf Modell speichern.
Beispielkonfigurationen
| Server | Base URL | Model ID |
|---|---|---|
| vLLM | https://your-server.com/v1 | Modellname beim vLLM-Start (z.B. meta-llama/Llama-3.1-70B-Instruct) |
| LiteLLM Proxy | https://your-litellm.com | Alias aus deiner LiteLLM-Konfiguration |
| Ollama | https://your-ollama.com/v1 | Name aus ollama list (z.B. llama3.1) |
Für Azure OpenAI verwende stattdessen das dedizierte Azure SDK. Es verwaltet API-Versionierung und deployment-basiertes URL-Routing automatisch.
Häufige Anwendungsfälle
- Datenschutz: betreibe Modelle auf deiner eigenen Infrastruktur, damit Prompts und Antworten in deinem Netzwerk bleiben.
- Kostenoptimierung: Open-Source-Modelle auf eigener Hardware können die Kosten bei hohem Volumen erheblich senken.
- Benutzerdefinierte Fine-Tuned-Modelle: deploye Modelle, die für spezifische Aufgaben oder Domänen fine-tuned wurden, mit vLLM oder ähnlichen Servern.
- Multi-Anbieter-Abstraktion: verwende LiteLLM als Proxy, um Anfragen von einem einzigen Interface aus an verschiedene Anbieter zu routen.
Fehlerbehebung
Verbindung verweigert oder Timeout: überprüfe, ob der Endpunkt von externen Servern über HTTPS erreichbar ist. Stelle sicher, dass deine Firewall eingehende Verbindungen erlaubt. Stelle sicher, dass dein Inferenzserver läuft und gesund ist.Authentifizierungsfehler: überprüfe deinen API-Schlüssel und prüfe, ob dein Endpunkt ein spezifischesBearer-Token-Format erwartet.Modell nicht gefunden: stelle sicher, dass die Model ID exakt mit dem übereinstimmt, was dein Inferenzserver erwartet (Groß-/Kleinschreibung beachten). Überprüfe, ob das Modell geladen und auf deinem Server verfügbar ist.Antworten werden abgeschnitten: überprüfe die Max Output Tokens Einstellung in Langdock und die Generierungslängenbeschränkungen deines Inferenzservers.Langsame Antworten: überprüfe den verfügbaren GPU-Speicher und die Rechenressourcen deines Servers. Erwäge quantisierte Modellversionen für schnellere Inferenz. Überwache die Queue-Länge und Skalierungskonfiguration deines Servers.Inkompatibles API-Format: nicht alle “OpenAI-kompatiblen” Server implementieren die vollständige API-Spezifikation. Überprüfe, ob dein Server den /v1/chat/completions-Endpunkt unterstützt und ob spezifische API-Versions-Header erforderlich sind.