Nutze Fallback-Modelle, um einem eigenen Modell mehrere Deployments zu geben. Das verbessert die Verfügbarkeit, wenn ein Endpunkt bei einem Anbieter, eine Region oder ein API-Schlüssel ein Limit erreicht oder nicht verfügbar ist.Documentation Index
Fetch the complete documentation index at: https://docs.langdock.com/llms.txt
Use this file to discover all available pages before exploring further.
So funktionieren Fallback-Modelle
Ein Fallback-Modell ist ein weiteres Deployment für dasselbe Modell. Du fügst es unter Deployment konfigurieren hinzu, indem du auf Weiteres Deployment hinzufügen klickst. Nutze Fallback-Modelle, wenn das ausgewählte Modell über einen anderen Endpunkt, eine andere Region oder einen anderen API-Schlüssel weiter antworten soll. Das Modell bleibt gleich, aber Langdock hat ein weiteres Deployment, das es versuchen kann, wenn ein Deployment limitiert oder nicht verfügbar ist. Jedes Deployment hat einen eigenen API-Schlüssel, einen eigenen Wert für Modellname / ID, ein optionales Token pro Minute Limit und einen Schalter zum Aktivieren. Langdock routet Anfragen über die aktivierten Deployments dieses Modells.Fallback-Modelle hinzufügen
Den vollständigen Ablauf findest du unter Eigene Modelle hinzufügen.- Gehe zu Workspace-Einstellungen -> Modelle und klicke auf Eigenes Modell hinzufügen.
- Wähle das Modell aus.
- Schließe die Modellkonfiguration ab, bis du Deployment konfigurieren erreichst.
- Klicke auf Weiteres Deployment hinzufügen.
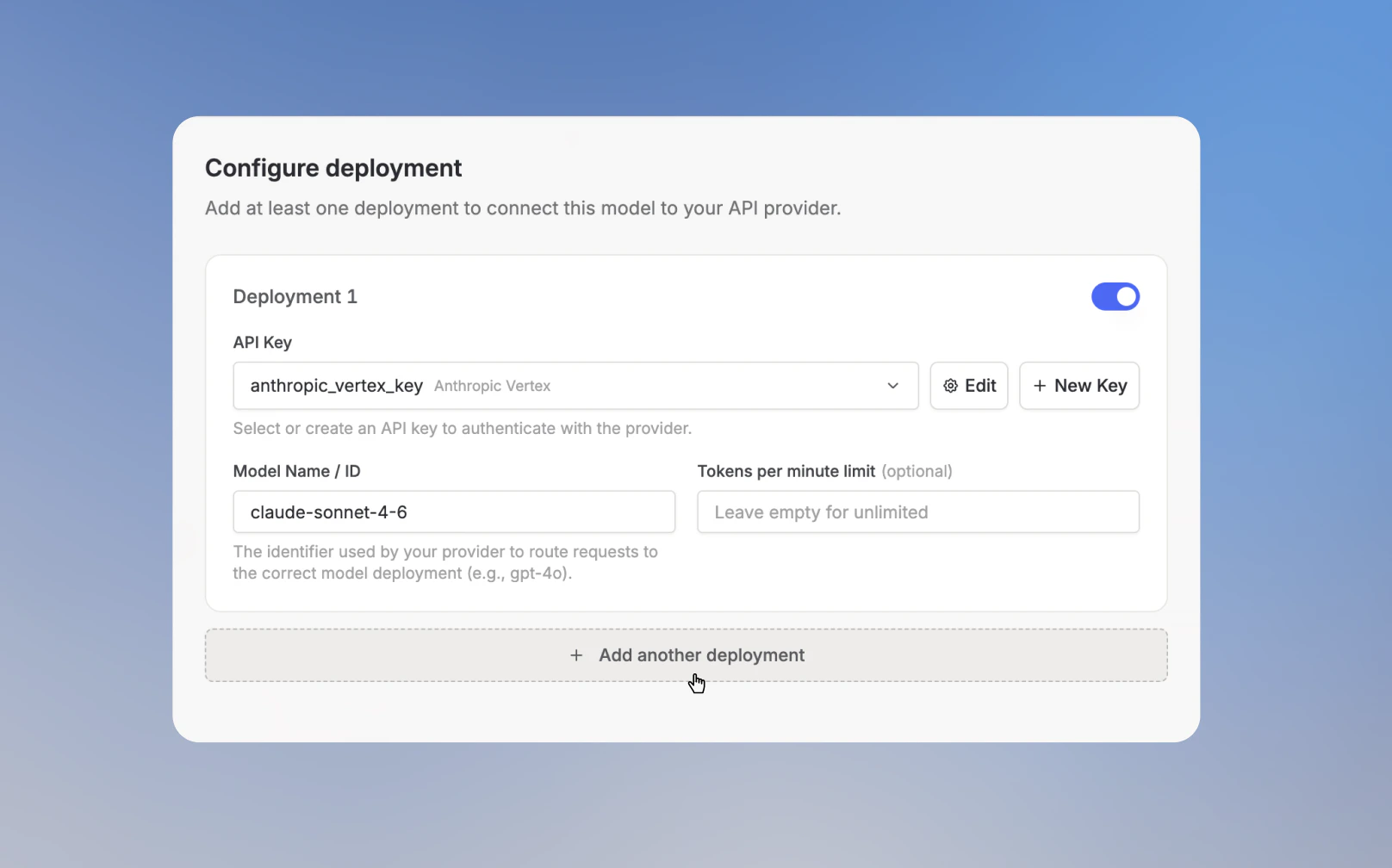
- Füge den API-Schlüssel und den Wert für Modellname / ID für das Fallback-Deployment hinzu.
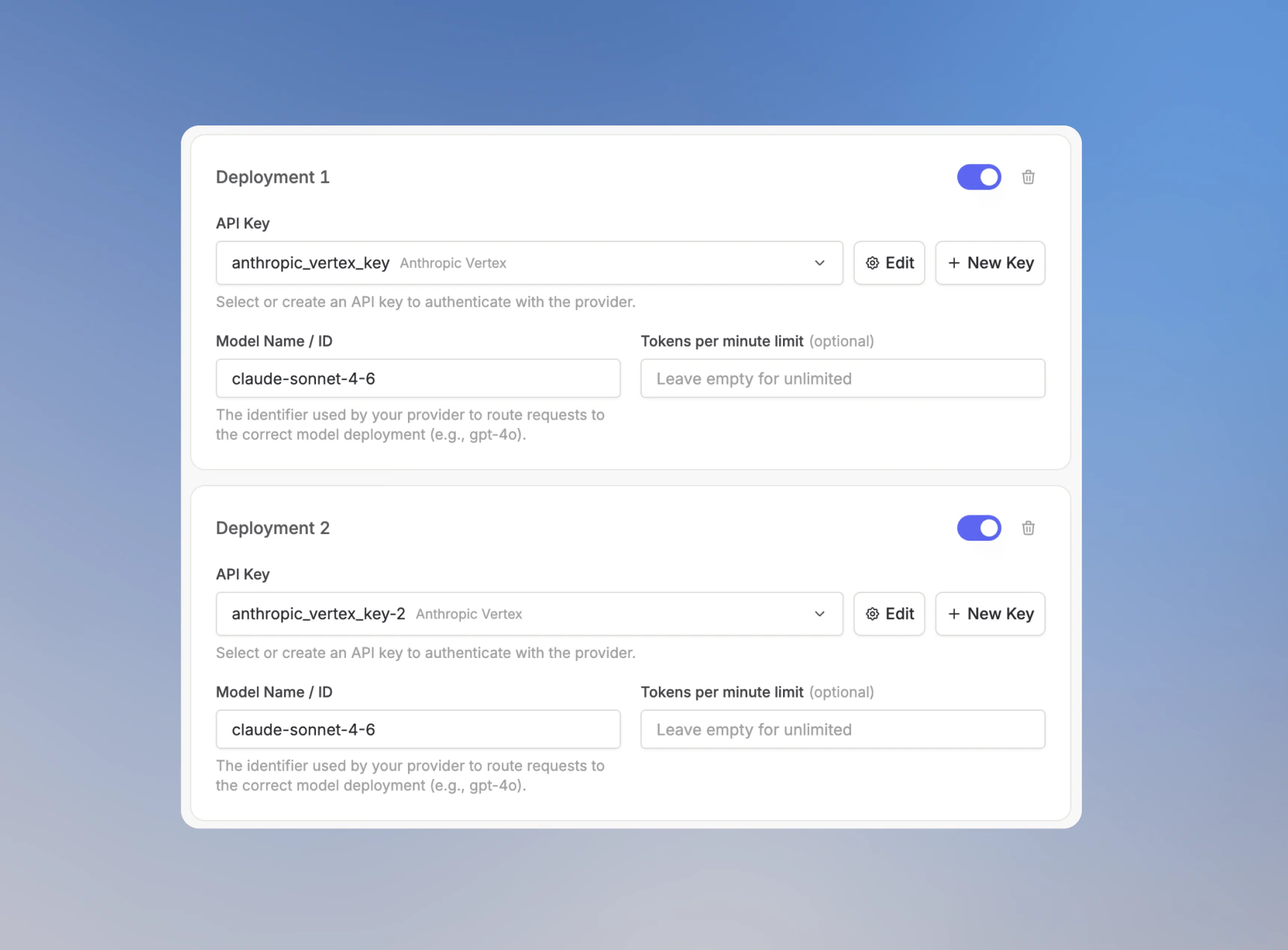
- Optional: Lege ein Token pro Minute Limit für das Fallback-Deployment fest.
- Klicke auf Testen & weiter und nach erfolgreichem Test auf Modell speichern.
So werden Anfragen geroutet
Langdock routet Anfragen über die aktivierten Deployments des ausgewählten Modells. Deaktivierte Deployments werden nicht verwendet.- Lege für jedes Deployment ein Token pro Minute Limit fest, wenn die Deployments unterschiedliche Kapazität haben. Deployments mit höheren Limits erhalten mehr Anfragen.
- Lass Token pro Minute Limit leer, wenn Deployments die Anfragen gleichmäßig teilen sollen. Langdock routet Anfragen reihum über verfügbare Deployments.
- Wenn ein Deployment sein Limit erreicht oder nicht verfügbar ist, versucht Langdock ein anderes aktiviertes Deployment.