Documentation Index
Fetch the complete documentation index at: https://docs.langdock.com/llms.txt
Use this file to discover all available pages before exploring further.
Wissensordner heißen jetzt Ordner. Du findest sie unter Dateien → Ordner.
Überblick
Der File-Search-Node fragt deine Ordner ab, um relevante Informationen und Kontext abzurufen. Verbinde deinen Workflow mit den Ordnern - durchsuche Dokumente, Dateien und Daten, die in Ordnern gespeichert sind, um KI-Antworten anzureichern, Informationen zu validieren oder Kontext für Entscheidungen bereitzustellen.Am besten für: Wissensabruf, Dokumentensuche, Kontext-Anreicherung, RAG
(Retrieval Augmented Generation) und Zugriff auf organisationales Wissen.
Wann du File Search verwenden solltest
Perfekt für:- Durchsuchen von Unternehmensdokumentation und Wissensdatenbanken
- Abrufen relevanten Kontexts für KI-Agent-Antworten
- Finden spezifischer Informationen über mehrere Dokumente hinweg
- Implementierung von RAG (Retrieval Augmented Generation) Mustern
- Validierung von Informationen gegen internes Wissen
- Anreicherung von Workflows mit Organisationsdaten
- Echtzeit-Web-Suche (verwende Web-Search-Node)
- Abrufen von Daten von externen APIs (verwende HTTP-Request-Node)
- Verarbeitung einzelner Dateien (verwende direkte Dateianhänge)
Konfiguration
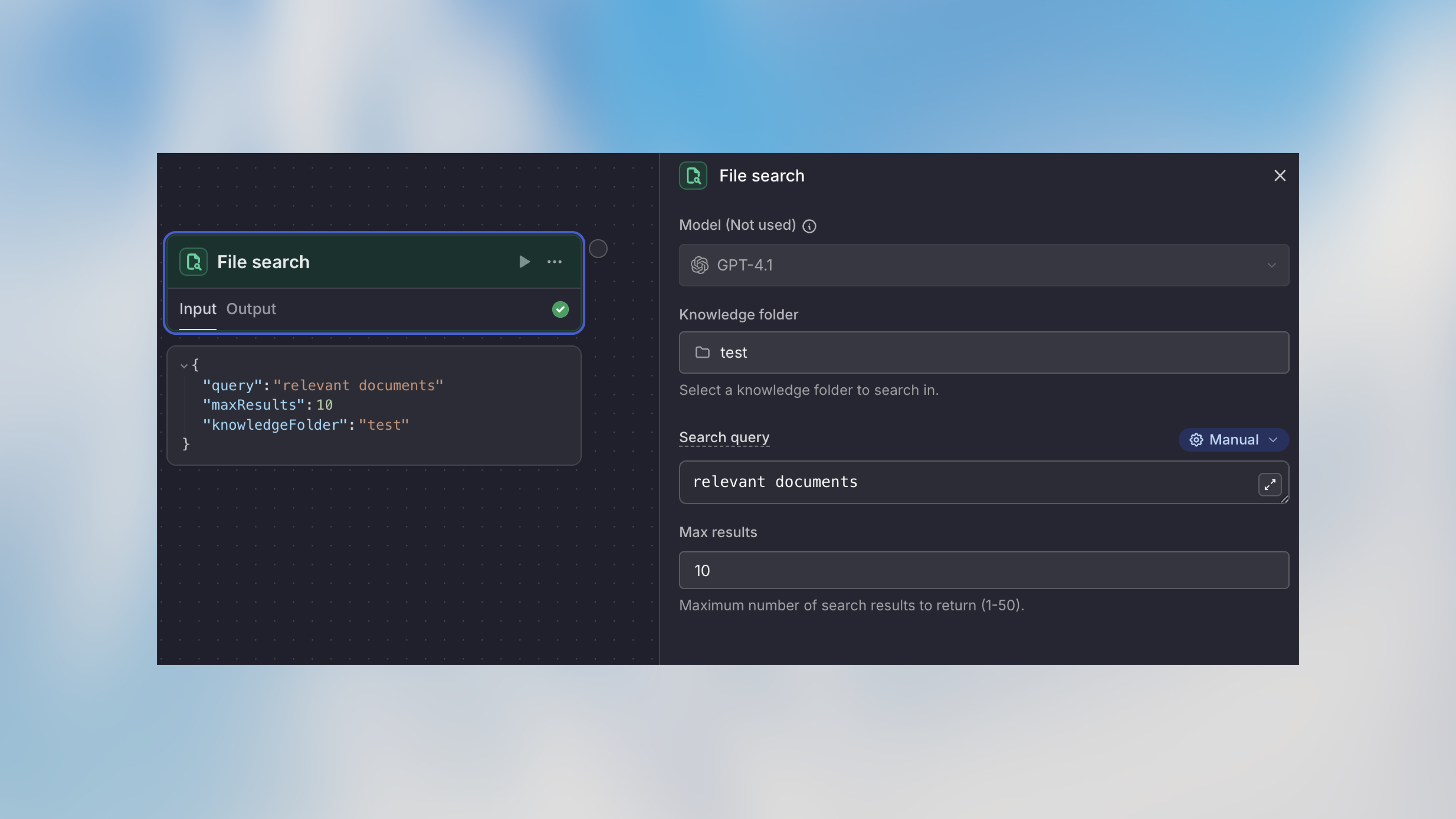
Ordner
Wähle den Ordner aus, den du aus den verfügbaren Ordnern deines Workspaces durchsuchen möchtest. Optionen:- Wähle aus verbundenen Ordnern
- Jeder Ordner enthält deine hochgeladenen Dokumente und Dateien
- Ordner unterstützen Dokumentdateien wie PDFs, Word-Docs und Textdateien. Tabellen und CSV-Dateien können nicht in Ordner hochgeladen werden.
Suchanfrage
Die Suchanfrage zum Finden relevanter Informationen. Unterstützt Manual-, Auto- und Prompt-AI-Modi. Manual-Modus-Beispiele:Max. Ergebnisse
Die maximale Anzahl relevanter Ergebnisse, die zurückgegeben werden sollen (Standard: 5) Empfehlungen:- 1-3 Ergebnisse: Fokussierte, spezifische Anfragen
- 5-10 Ergebnisse: Breiterer Kontext benötigt
- 10+ Ergebnisse: Umfassende Suchen (kann Performance beeinflussen)
Wie es funktioniert
- Anfrage wird gegen den ausgewählten Ordner verarbeitet
- Semantische Suche findet die relevantesten Dokument-Chunks
- Ergebnisse werden nach Relevanz-Score sortiert
- Top-N-Ergebnisse werden basierend auf Max-Ergebnisse-Einstellung zurückgegeben
- Abgerufene Informationen sind für nachfolgende Nodes verfügbar
Beispiel-Anwendungsfälle
Kundensupport mit Wissensdatenbank
Produktinformations-Suche
Dokumentenvalidierung
Auf Suchergebnisse zugreifen
Greife auf die abgerufenen Informationen in nachfolgenden Nodes zu:Ergebnis-Struktur
Jedes Ergebnis enthält:- text: Der relevante Text-Chunk aus dem Dokument
- similarity: Relevanz-Score (0-1, höher ist relevanter)
- fileName: Name der Quelldatei
- fileUrl: URL zum Zugriff auf die Quelldatei
- mimeType: MIME-Typ der Quelldatei
- subsource: Zusätzliche Quellreferenz
- subname: Zusätzliche Namensreferenz
- fileId: Eindeutige Kennung der Quelldatei
- externalId: Externe Referenz-ID aus dem verbundenen Quellsystem
- fileSize: Größe der Datei in Bytes
- connectionId: ID der Integrationsverbindung, die die Datei bereitgestellt hat
- syncParams: Synchronisierungsparameter aus der Quellintegration
- pageCount: Anzahl der Seiten in der Datei
Einschränkungen
- Ordner-Umfang: Durchsucht nur innerhalb des ausgewählten Ordners
- Ergebnisqualität: Hängt von Qualität und Vollständigkeit der hochgeladenen Dokumente ab
- Chunk-Größe: Große Dokumente werden in Chunks aufgeteilt; relevante Informationen könnten sich über mehrere Ergebnisse erstrecken
- Echtzeit-Updates: Dokumentänderungen erfordern Neuverarbeitung, bevor sie in Suchergebnissen erscheinen
Wichtig: Stelle sicher, dass deine Ordner regelmäßig mit aktuellen Informationen aktualisiert werden, um genaue Suchergebnisse zu erhalten.
Best Practices
Schreibe spezifische Suchanfragen
Schreibe spezifische Suchanfragen
Spezifischere Anfragen liefern relevantere Ergebnisse. Füge Schlüsselbegriffe, Produktnamen oder Themen hinzu, anstatt generischer Suchen.
Passe Max. Ergebnisse basierend auf Anwendungsfall an
Passe Max. Ergebnisse basierend auf Anwendungsfall an
Beginne mit 5 Ergebnissen und passe basierend auf Antwortqualität an. Zu wenige könnten wichtigen Kontext verpassen, zu viele können Relevanz verwässern.
Halte Ordner organisiert
Halte Ordner organisiert
Organisiere Ordner nach Thema oder Bereich für gezieltere Suchen. Trenne technische Docs von Marketing-Inhalten.
Kombiniere mit Agent-Nodes
Kombiniere mit Agent-Nodes
File Search ist am leistungsfähigsten in Kombination mit Agent-Nodes. Der Agent kann die abgerufenen Informationen synthetisieren und interpretieren.
Teste mit echten Anfragen
Teste mit echten Anfragen
Teste deine File Search mit tatsächlichen Fragen, die Benutzer stellen könnten, um sicherzustellen, dass Ordner-Inhalte ausreichend sind und Anfragen relevante Ergebnisse liefern.
Handle keine Ergebnisse
Handle keine Ergebnisse
Füge eine Bedingung nach File Search hinzu, um Fälle zu behandeln, in denen keine relevanten Ergebnisse gefunden werden. Stelle Fallback-Antworten oder Eskalationspfade bereit.
Nächste Schritte
Agent-Node
Verarbeite und synthetisiere Suchergebnisse mit KI
Ordner
Lerne, wie du Ordner einrichtest und verwaltest
Web-Suche
Durchsuche das Internet nach aktuellen Informationen
Condition-Node
Route basierend auf Suchergebnisqualität