Documentation Index
Fetch the complete documentation index at: https://docs.langdock.com/llms.txt
Use this file to discover all available pages before exploring further.
Einführung
Variablen sind das Herzstück deiner Workflows – sie transportieren Daten zwischen Nodes und machen deine Automatisierungen dynamisch und kontextbewusst. Jedes Mal, wenn ein Node seine Ausführung abschließt, wird sein Output als Variable verfügbar, auf die nachfolgende Nodes zugreifen und sie verwenden können.Stell dir Variablen wie Container vor, die Daten enthalten, während sie durch deinen Workflow fließen. Zu verstehen, wie du auf sie zugreifst und sie manipulierst, ist der Schlüssel zum Erstellen leistungsstarker Automatisierungen.
Auf Variablen zugreifen
Langdock bietet dir zwei intuitive Möglichkeiten, auf Variablen von vorherigen Nodes in deinem Workflow zuzugreifen:Methode 1: Doppelte geschweifte Klammern ({{}})
Der direkteste Weg, Variablen zu referenzieren, ist die Verwendung der doppelten geschweiften Klammer-Syntax. Tippe einfach {{ in ein beliebiges Feld, und du siehst ein Dropdown aller verfügbaren Variablen von vorherigen Nodes.
Grundlegende Syntax:
Methode 2: Output-Selektor
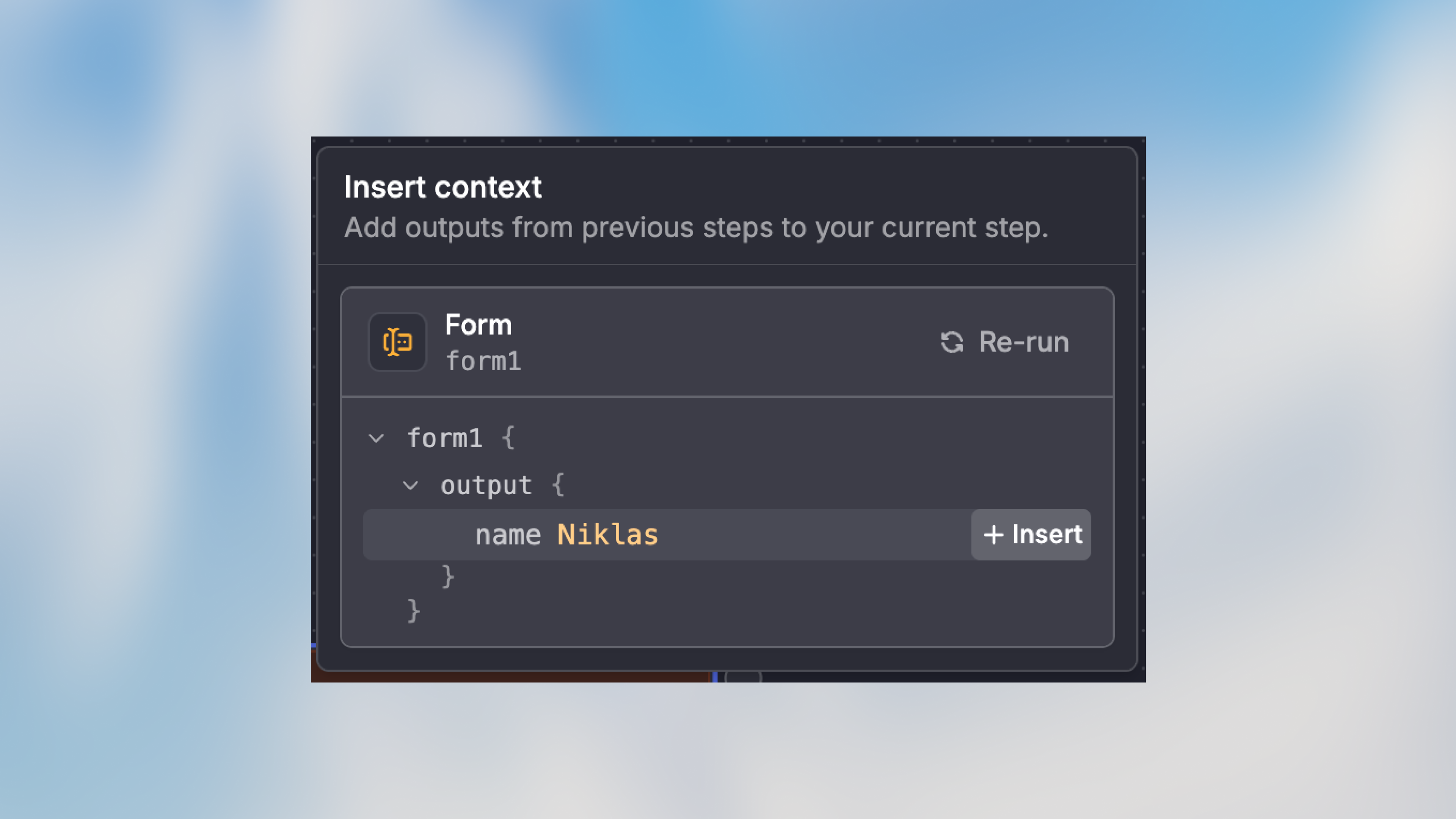
- Klicke auf ein Feld, das Variablenauswahl unterstützt
- Such nach dem Variablen-Picker-Symbol oder Dropdown
- Durchsuche verfügbare Outputs von vorherigen Nodes
- Wähle genau das Feld aus, das du benötigst
Variablenstruktur verstehen
Variablen folgen einer konsistenten Struktur, die sie vorhersehbar und einfach zu verwenden macht:node_name: Der eindeutige Name, den du dem Node gegeben hast (z.B.form1,analyze_data,http_request)output: Das Standard-Output-Objekt, das jeder Node produziertproperty: Das spezifische Datenfeld, auf das du zugreifen möchtest
Auf verschachtelte Daten zugreifen
Reale Daten haben oft verschachtelte Strukturen. Du kannst auf tief verschachtelte Eigenschaften mit Punkt-Notation zugreifen:Mit Arrays arbeiten
Wenn deine Daten Arrays enthalten, kannst du auf bestimmte Elemente per Index zugreifen:Agent-Output-Struktur
Agent-Nodes haben zwei Output-Typen je nach Konfiguration: Wenn ein Output-Schema definiert ist:structured-Eigenschaft existiert nur, wenn du ein Output-Schema im Agent-Node konfiguriert hast. Ohne Schema verwende das messages-Array, um auf die Konversation zuzugreifen.
Optional Chaining mit ?
Verwende ?, um sicher auf Eigenschaften zuzugreifen, die möglicherweise nicht existieren:
undefined oder null ist, gibt der gesamte Ausdruck undefined zurück, anstatt einen Fehler zu werfen.
Was passiert, wenn du Nodes umbenennst
Node-Namen sind mit Variablen verknüpft. Wenn du einen Node umbenennst, werden alle Variablen, die auf diesen Node verweisen, automatisch in deinem gesamten Workflow aktualisiert – keine manuellen Korrekturen nötig.
Automatische Variablen-Updates
Nehmen wir an, du hast einen Formular-Trigger-Node namensform1, der an mehreren Stellen verwendet wird:
form1 in PMApplicantForm umbenennst, werden alle Referenzen automatisch aktualisiert:
- Manuellen Modus-Feldern
- AI Prompt Modus-Anweisungen
- Code-Node-Referenzen
- Condition-Node-Vergleichen
- Allen anderen Node-Konfigurationen
Best Practice: Benenne Nodes aussagekräftig
Da Umbenennung nahtlos funktioniert, investiere Zeit in klare, beschreibende Namen von Anfang an: Gute Node-Namen:ExtractCustomerDataAnalyzeSentimentSendWelcomeEmailCheckInventoryStatus
- ❌
agent1 - ❌
http_node - ❌
trigger - ❌
action
Variablen über mehrere Nodes hinweg wiederverwenden
Eines der leistungsstärksten Features von Variablen ist, dass du sie mehrfach über viele verschiedene Nodes hinweg verwenden kannst. Sobald ein Node Output produziert, sind diese Daten für alle nachfolgenden Nodes in deinem Workflow verfügbar.Grundlegende Variablen-Wiederverwendung
Verwende dieselbe Variable in mehreren Nodes:form1.output zugreifen, da sie alle nach dem Trigger kommen.
Anwendungsfall: Multi-Channel-Benachrichtigungen
Sende dieselben Informationen über verschiedene Kanäle:Fortgeschrittene Variablen-Techniken
Mehrere Variablen kombinieren
Mische Daten von verschiedenen Nodes in einem einzelnen Feld:Variablen in Code-Nodes
Nutze Code-Nodes, um in eigenem Code auf Variablen zuzugreifen. Mehr über Code-Nodes erfahren.Variablen im AI Prompt-Modus
Referenziere mehrere Variablen in KI-Anweisungen:Filtern und Transformieren
Verwende Variablen zum Filtern oder Transformieren von Daten: In einem Condition-Node:Der gesamte Ausdruck muss innerhalb von
{{ }} stehen. Der Ausdruck wird als JavaScript ausgewertet.Variablen-Troubleshooting
Variable nicht verfügbar
Problem: Die Variable, die du möchtest, erscheint nicht im Autocomplete. Häufige Ursachen:- Der Node wurde noch nicht verbunden
- Der Node kommt nachgelagert (nach) dem aktuellen Node
- Der Node wurde in einem Testlauf noch nicht ausgeführt
Undefined oder Null-Werte
Problem: Variable existiert, gibt aberundefined oder null zurück.
Häufige Ursachen:
- Der Quell-Node ist fehlgeschlagen oder hat leere Daten zurückgegeben
- Der Feldpfad ist inkorrekt
- Optionale Daten wurden nicht bereitgestellt
Falscher Datentyp
Problem: Variable enthält unerwarteten Datentyp. Lösung: Überprüfe den Output-Tab des Quell-Nodes nach einem Testlauf, um die tatsächliche Datenstruktur zu sehen.Schnellreferenz
Variablen-Syntax Spickzettel
| Anwendungsfall | Syntax | Beispiel |
|---|---|---|
| Grundlegender Feldzugriff | {{node.output.field}} | {{trigger.output.email}} |
| Verschachteltes Objekt | {{node.output.object.property}} | {{user.output.profile.age}} |
| Array-Element | {{node.output.array[index]}} | {{items.output.list[0]}} |
| Verschachtelt im Array | {{node.output.array[0].property}} | {{orders.output.items[0].price}} |
| Gesamtes Array | {{node.output.array}} | {{trigger.output.tags}} |
| Agent strukturierter Output | {{agent.output.structured.field}} | {{analyze.output.structured.summary}} |
| Optional Chaining | {{node.output.field?.property}} | {{trigger.output.user?.email}} |
| Mehrere in einem String | Bestellung {{id}} über {{amount}} | Bestellung {{trigger.output.id}} über {{trigger.output.amount}} |
Best Practices
Verwende beschreibende Node-Namen
Verwende beschreibende Node-Namen
Benenne Nodes klar, damit Variablen selbstdokumentierend sind:
{{AnalyzeCustomerFeedback.output.sentiment}} ist viel klarer als {{agent1.output.sentiment}}Teste Variablen nach jedem Node
Teste Variablen nach jedem Node
Nachdem du einen Node hinzugefügt hast, führe einen Test aus und klicke auf den Node, um seinen Output zu inspizieren. Dies bestätigt die Datenstruktur, bevor du sie in nachgelagerten Nodes verwendest.
Stelle Fallback-Werte bereit
Stelle Fallback-Werte bereit
Verwende Standardwerte für optionale Felder:
Halte Variablenpfade einfach
Halte Variablenpfade einfach
Wenn du dich dabei erwischst, tief verschachtelte Pfade wie
{{node.output.data.items[0].meta.tags[2].value}} zu schreiben, erwäge die Verwendung eines Code-Nodes, um die Datenstruktur zuerst zu vereinfachen.Dokumentiere komplexe Variablen-Nutzung
Dokumentiere komplexe Variablen-Nutzung
Füge Kommentare in Code-Nodes oder Beschreibungen in Nodes hinzu, wenn du komplexe Variablen-Logik verwendest, besonders für Team-Workflows.
Nächste Schritte
Jetzt, da du Variablen verstehst, erkunde, wie du sie effektiv in verschiedenen Kontexten verwenden kannst:Field-Modi
Lerne, wie du Variablen in Auto-, Manual- und AI Prompt-Modi verwendest
Code-Node
Transformiere und manipuliere Variablen mit benutzerdefiniertem Code
Condition-Node
Verwende Variablen, um dynamische Routing-Logik zu erstellen
Kernkonzepte
Verstehe, wie Variablen ins große Ganze passen