Documentation Index
Fetch the complete documentation index at: https://docs.langdock.com/llms.txt
Use this file to discover all available pages before exploring further.
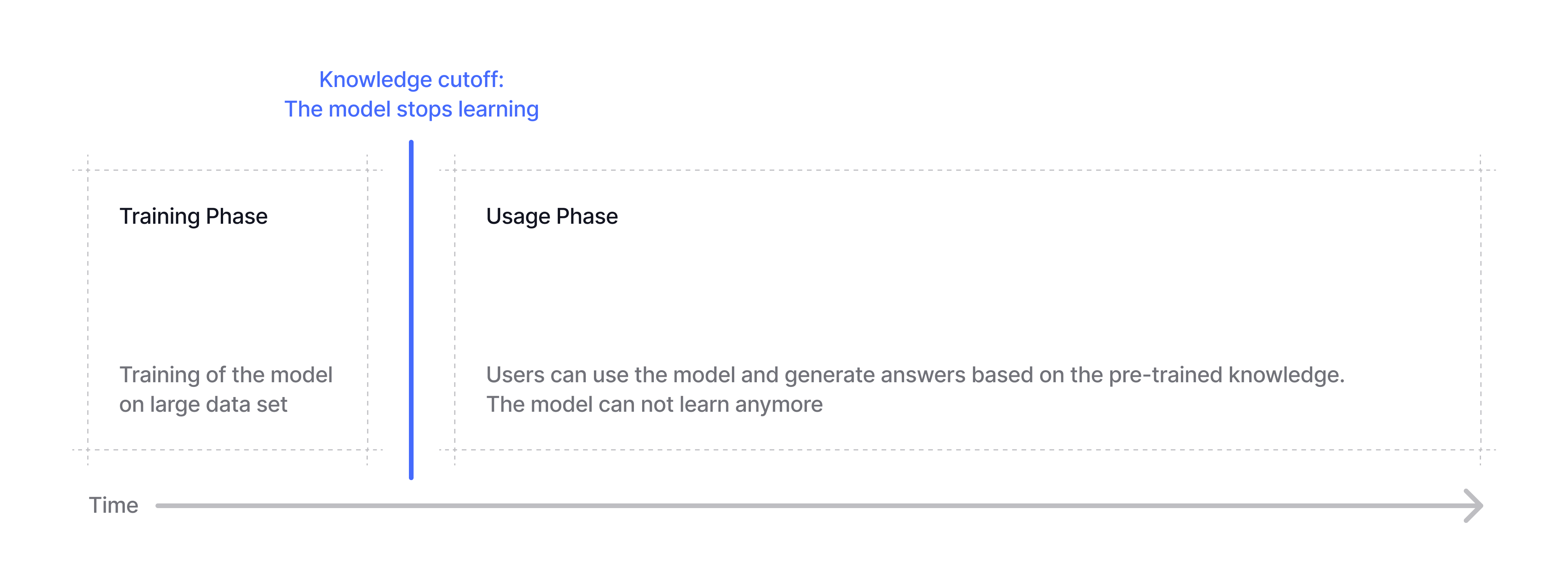
The life cycle of an AI model
A Large Language Model (LLM) undergoes two main phases:- The training phase
- The model is trained on large data sets
- The usage phase
- The model can be used to generate an answer
- The model can not learn anymore
Training an LLM
What is a Token? A token is a piece of text (roughly a word or word fragment) that the model processes. On average, 1 token equals about 4 characters. For example, “Hello world” is 2 tokens, while “understanding” might be split into 2 tokens: “under” and “standing”.

Using an LLM
What is Inference? Inference is the phase when a trained AI model generates responses to your prompts. Unlike training (when the model learns), during inference the model uses its existing knowledge to predict and generate text. The model cannot learn new information during this phase.
Artificial Intelligence, the model assigns much higher probability to related terms like machine learning than unrelated ones like banana cake.
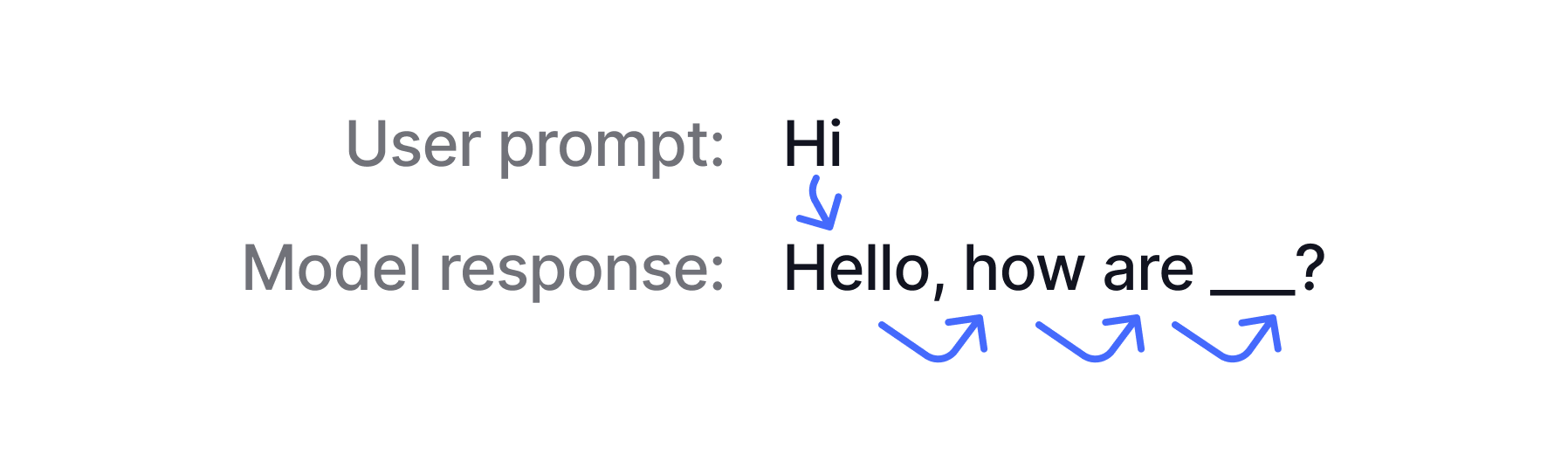
Hi, the model assigns high probability to greeting tokens, so it generates Hello as the response.
Then, it generates the next most likely word based on Hi Hello. This process is repeated until the model decides the request was sufficiently answered.
The generation process works token by token:
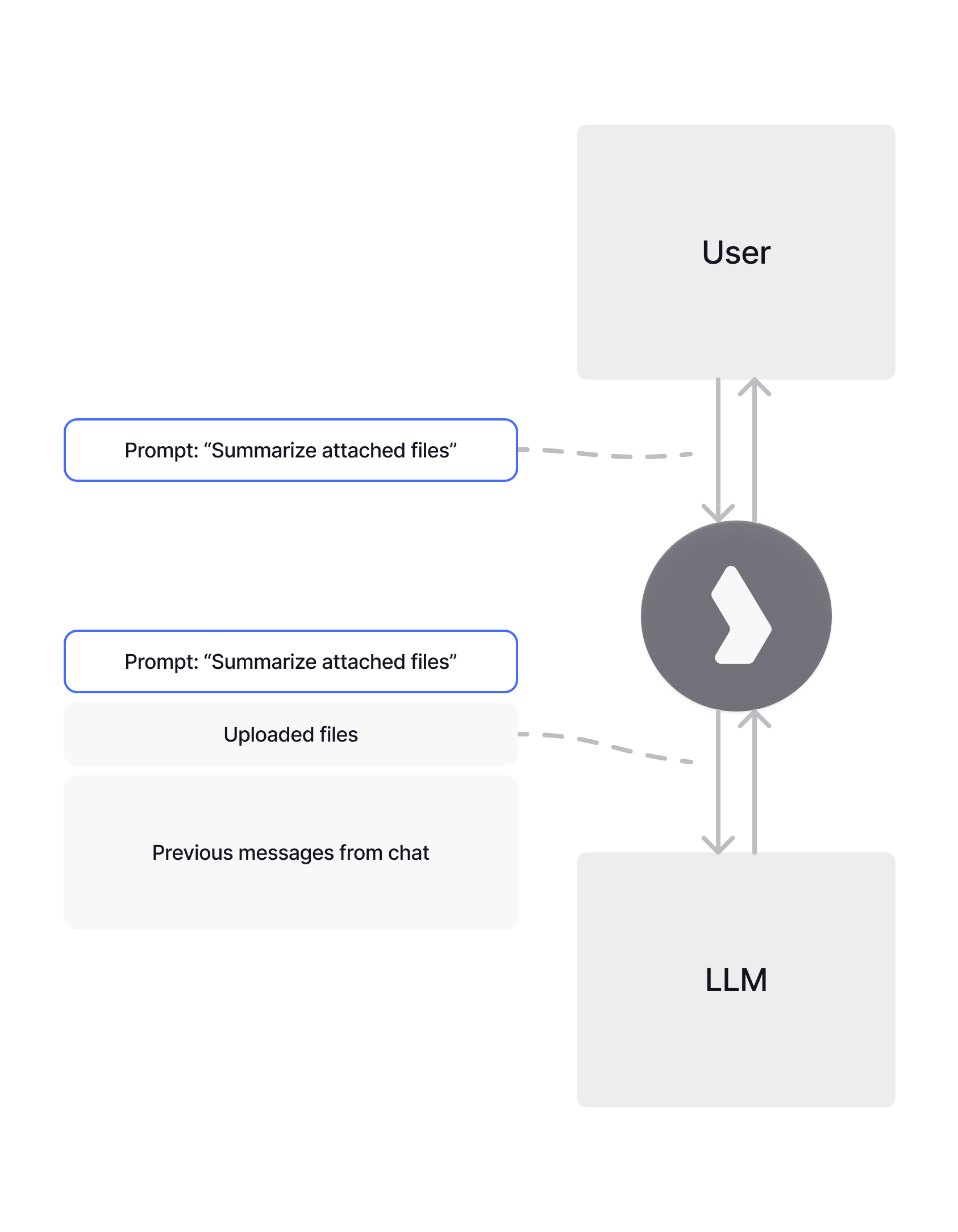
- User sends:
Hi - Model predicts high probability for greeting tokens like
Hello - Model then predicts the next token based on
Hi Hello - This continues until the model generates an end-of-sequence token
Influencing the output of a response
What is a Context Window? The context window is the maximum amount of text (measured in tokens) that an AI model can process in a single request. Think of it as the model’s “working memory” - everything you want the model to consider (your current message, chat history, attached documents, instructions) must fit within this limit.