Der Lebenszyklus eines KI-Modells
Ein Large Language Model (LLM) durchläuft zwei Hauptphasen:
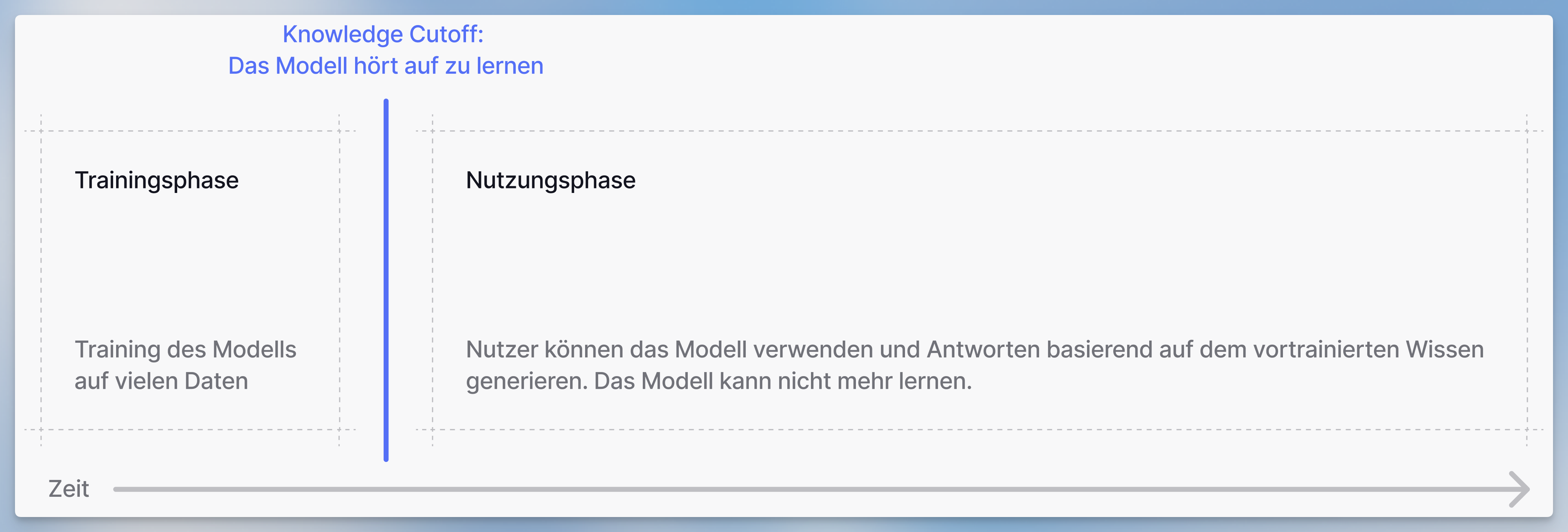
- Die Trainingsphase
- Das Modell wird auf großen Datensätzen trainiert
- Die Nutzungsphase
- Das Modell kann verwendet werden, um eine Antwort zu generieren
- Das Modell kann nicht mehr lernen
Training eines LLM
Was ist ein Token? Ein Token ist ein Textstück (ungefähr ein Wort oder
Wortfragment), das das Modell verarbeitet. Im Durchschnitt entspricht 1 Token
etwa 4 Zeichen. Zum Beispiel ist “Hallo Welt” 2 Tokens, während “Verständnis”
möglicherweise in 2 Tokens aufgeteilt wird: “Ver” und “ständnis”.
 Zum Beispiel wird es getestet, um Lücken in einem Text zu füllen. Damit lernt es Wahrscheinlichkeiten von Wörtern in verschiedenen Situationen (mehr dazu unten).
Nachdem das Modell vollständig trainiert ist, kann es nicht mehr lernen. Das Datum, an dem das Training des Modells beendet wird, wird als “Knowledge Cutoff Date” bezeichnet, da das Modell nur Fakten bis zu diesem Datum gelernt hat und nichts weiß, was danach passiert.
Schauen wir uns nun an, wie diese trainierten Modelle tatsächlich Antworten generieren.
Zum Beispiel wird es getestet, um Lücken in einem Text zu füllen. Damit lernt es Wahrscheinlichkeiten von Wörtern in verschiedenen Situationen (mehr dazu unten).
Nachdem das Modell vollständig trainiert ist, kann es nicht mehr lernen. Das Datum, an dem das Training des Modells beendet wird, wird als “Knowledge Cutoff Date” bezeichnet, da das Modell nur Fakten bis zu diesem Datum gelernt hat und nichts weiß, was danach passiert.
Schauen wir uns nun an, wie diese trainierten Modelle tatsächlich Antworten generieren.
Verwendung eines LLM
Was ist Inferenz? Inferenz ist die Phase, in der ein trainiertes KI-Modell
Antworten auf deine Prompts generiert. Im Gegensatz zum Training (wenn das
Modell lernt) nutzt das Modell während der Inferenz sein bestehendes Wissen,
um Text vorherzusagen und zu generieren. Das Modell kann während dieser Phase
keine neuen Informationen lernen.
Künstlicher Intelligenz fragst, weist das Modell verwandten Begriffen wie Machine Learning eine viel höhere Wahrscheinlichkeit zu als unverwandten Begriffen wie Bananenkuchen.
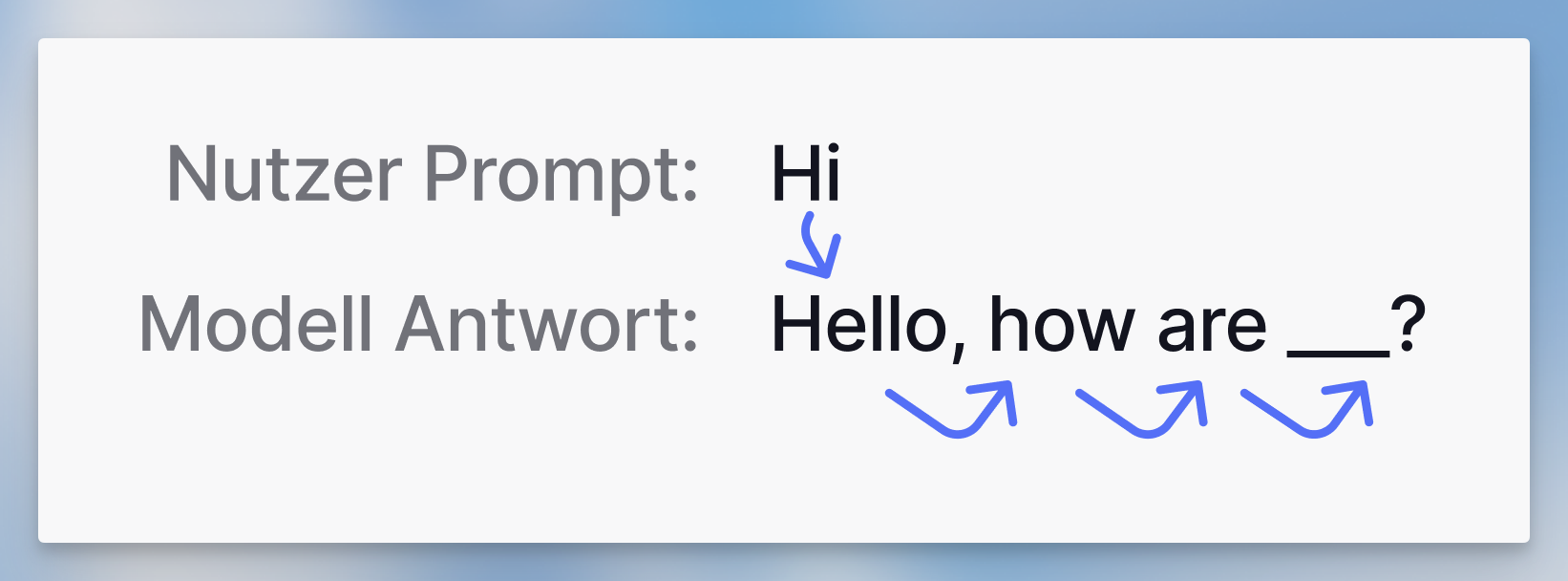 Wenn ein Nutzer eine Anfrage an das Modell sendet, wählt das Modell das nächste Wort oder Wortteil (Token) basierend auf diesen Wahrscheinlichkeiten aus.
Zum Beispiel lässt das Wort
Wenn ein Nutzer eine Anfrage an das Modell sendet, wählt das Modell das nächste Wort oder Wortteil (Token) basierend auf diesen Wahrscheinlichkeiten aus.
Zum Beispiel lässt das Wort Hi vom Nutzer das Modell wahrscheinlich mit einem Gruß antworten. Es antwortet mit Hallo.
Dann generiert es das nächste wahrscheinlichste Wort basierend auf Hi und Hallo. Dieser Prozess wird wiederholt, bis das Modell entscheidet, dass die Anfrage ausreichend beantwortet wurde.
Beeinflussung der Ausgabe einer Antwort
Was ist ein Context Window? Das Context Window (Kontextfenster) ist die
maximale Textmenge (gemessen in Tokens), die ein KI-Modell in einer einzelnen
Anfrage verarbeiten kann. Denke daran als “Arbeitsspeicher” des Modells -
alles, was das Modell berücksichtigen soll (deine aktuelle Nachricht,
Chat-Verlauf, angehängte Dokumente, Anweisungen), muss in dieses Limit passen.
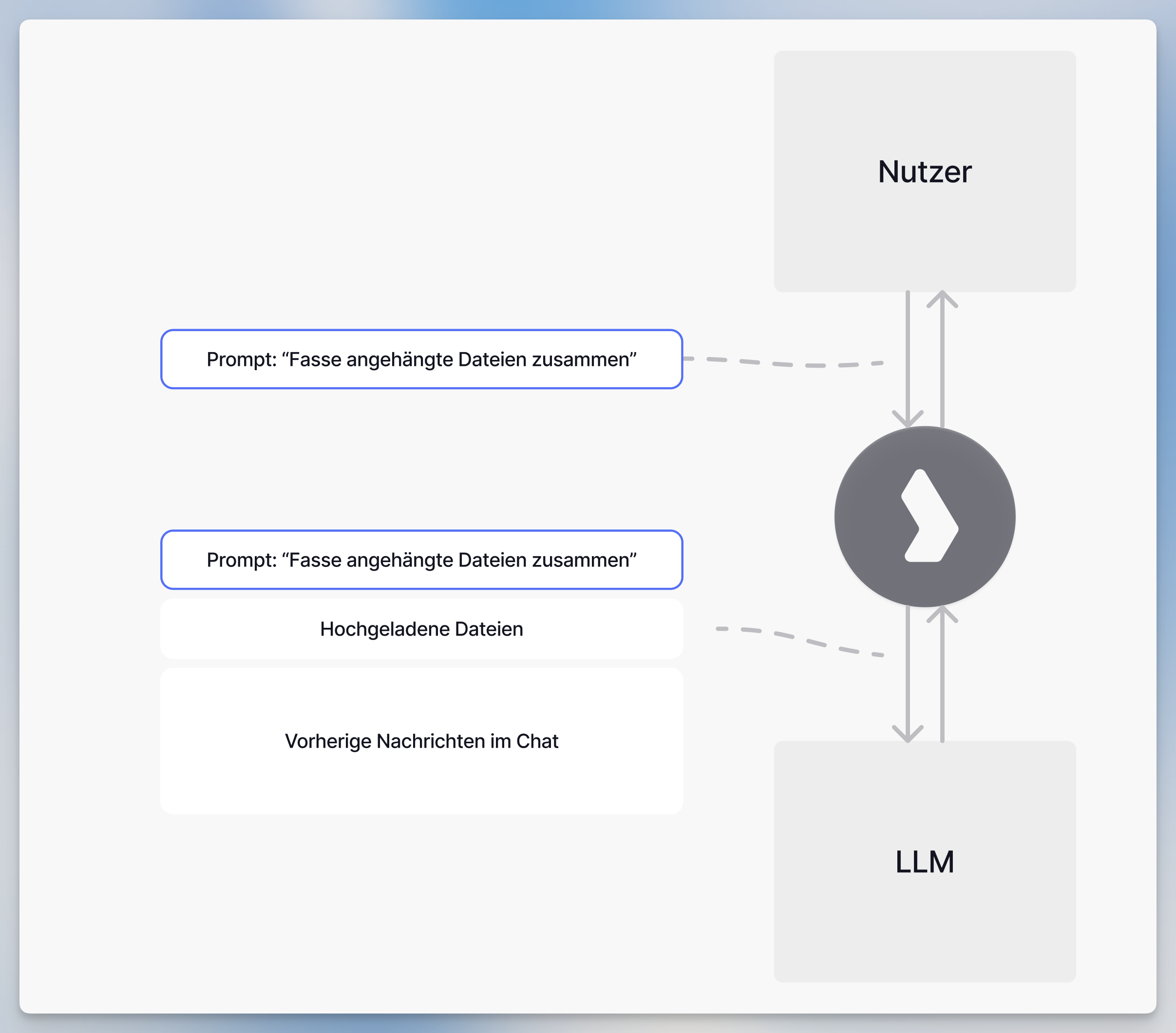 Jede Anfrage an das Modell enthält alles, was für diese spezifische Antwort benötigt wird: deine aktuelle Nachricht, die gesamte Chat-Historie, angehängte Dokumente, Systemanweisungen und alle relevanten Inhalte aus der Wissensdatenbank. Dieser vollständige Kontext wird in das Context Window des Modells gepackt (die maximale Textmenge, die es in einer einzigen Anfrage verarbeiten kann).
Das Modell behandelt jede Anfrage als völlig unabhängig, aber durch die Einbeziehung des gesamten relevanten Kontexts kann es kohärente Gespräche führen und auf vorherige Informationen verweisen.
Jede Anfrage an das Modell enthält alles, was für diese spezifische Antwort benötigt wird: deine aktuelle Nachricht, die gesamte Chat-Historie, angehängte Dokumente, Systemanweisungen und alle relevanten Inhalte aus der Wissensdatenbank. Dieser vollständige Kontext wird in das Context Window des Modells gepackt (die maximale Textmenge, die es in einer einzigen Anfrage verarbeiten kann).
Das Modell behandelt jede Anfrage als völlig unabhängig, aber durch die Einbeziehung des gesamten relevanten Kontexts kann es kohärente Gespräche führen und auf vorherige Informationen verweisen.