Integrations
Overview of all integrations at Langdock.
Langdock is built for using AI to work with your internal company knowledge. To process this knowledge effectively, we provide different integrations. Every day, our system will check for updates in the selected items and re-import these automatically, including subfolders.
How to open the integrations menu
To connect your integrations, go to the chat and select the “custom” chat in the lower left corner of the chat field. You will now see a window with the integrations menu.
Another way to get here is to click on ”+ File” next to the model selector and then on “Select files”.
Integration Types
Files
You can upload text-based files to Langdock. The supported file types are PDF, docx, md, txt and ppt. But in the files, Langdock can only process texts. If you upload a presentation with many images, the context might not be understood completely, and response quality could decrease.
There is no limit to how many files you can upload, although the fewer files you select for your prompt or assistant, the better the responses will be.
Web
You can add websites by adding a URL. If you want to, you can also import subpages - so if you enter https://langdock.com/, the tool also searches through https://langdock.com/pricing to answer your prompt.
When it comes to web crawling, different strategies can be employed to navigate and index the content of a domain. Here’s an explanation of the three crawling modes you can use:
Load All Pages of the Domain
-
This mode involves the crawler systematically visiting every page that it can find on a specific domain. The crawler starts from a known page, often the homepage, and follows every link it encounters that leads to another page within the same domain until all reachable pages have been loaded.
-
This approach is comprehensive and ensures that every public page on the domain is crawled, even content not linked from the main pages or sitemap. However, it is the most time-consuming option and can take a long time to complete
Load Children of the Webpage
-
In this mode, the crawler is focused on a specific webpage and only loads pages directly linked from this page, often referred to as its “children.” This is a more targeted approach where the crawler doesn’t aim to index the entire domain but is interested in directly reachable content from a specific starting point.
-
This is a faster and more efficient approach than the previous one. It can miss important content if it is not linked on the target page, so it is useful when exploring a field of related content
Use the Sitemap of the Domain
-
Many websites provide sitemaps, which list the URLs of a site along with additional metadata about each URL (like when it was last updated, how often it changes, and its importance relative to other URLs). Crawlers can use this information to index the site more intelligently.
-
The sitemap allows the crawler to work more efficiently and prioritize essential changes. The downside is that only some sites have sitemaps, and some might need to be updated, which decreases the effectiveness of the crawling.
Please remember that some pages and services restrict crawling them technically (crawlers are blocked) or legally (restricting crawling in their terms).
Text
If you have a very long text (like an email thread or pasted text from a different source), you can save it in Langdock without having to save it elsewhere and then upload it to Langdock. Once you select the text, it will behave the same as a PDF or other files.
One more thing to consider: We increased the context window here, so if you want to process a long text with complete text retrieval, you can do this here.
Confluence, Notion, Google Drive, OneDrive, Sharepoint and Slack
On the left, you can see different integrations. Connecting each tool works very similarly. Let’s go through connecting a Google Drive as an example step by step:
-
Select the integration you want to connect in the list on the left. In our case, this is Google Drive.
-
You should see a “Connect your Google Drive account” screen. Press the button “Connect” in the centre.
-
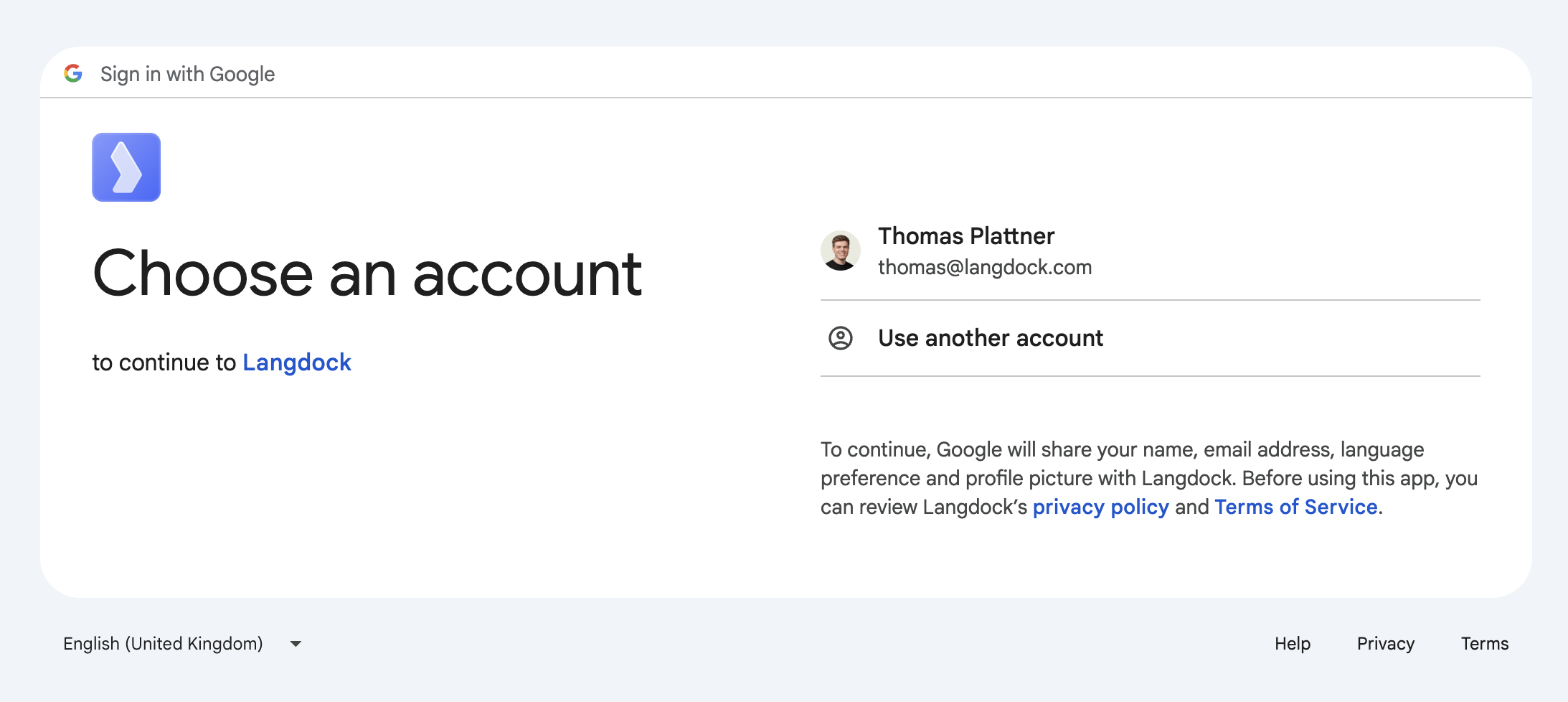
You are redirected to the integration process of the individual tool. The design looks different in each tool, but the steps are the same. In the first step, please select the account you want to connect:
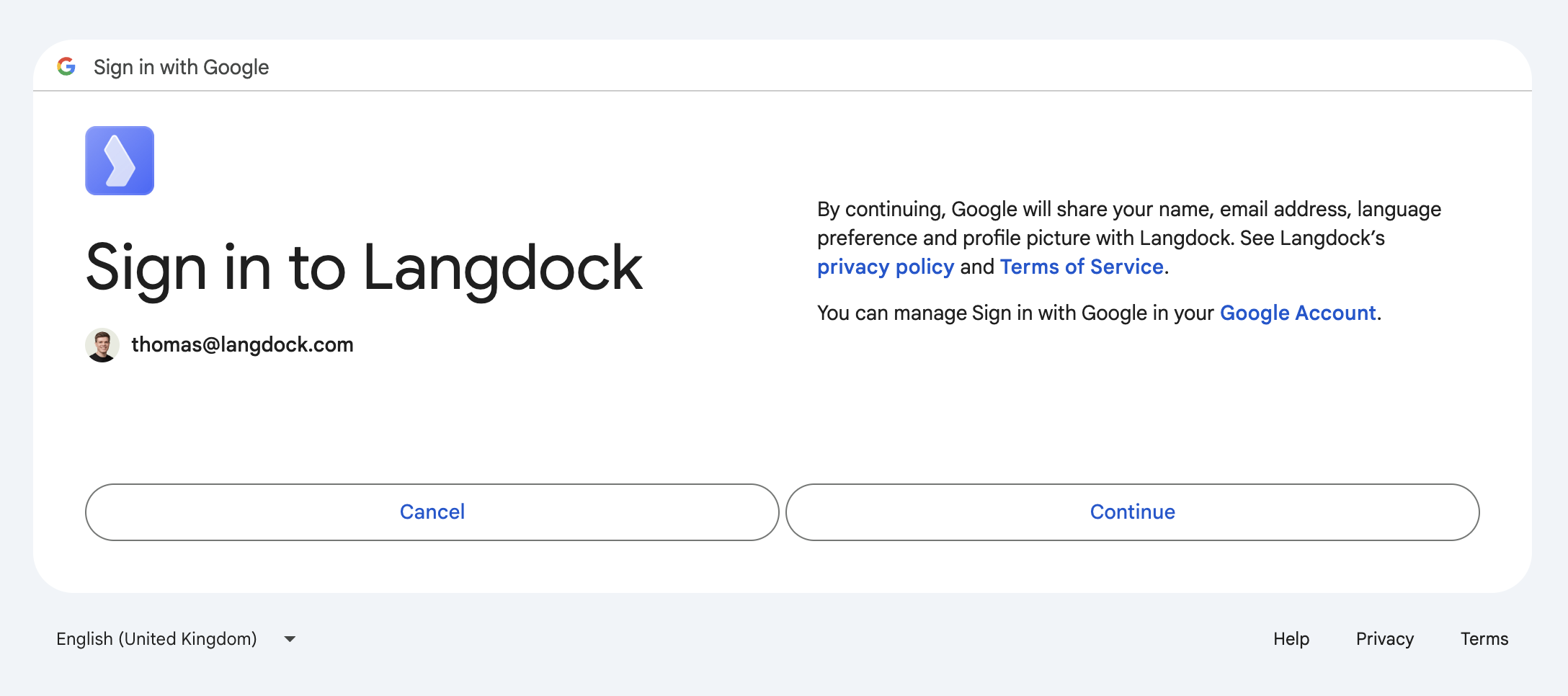
- You are asked whether you want to continue because data will be shared with Langdock. Click “Continue”.
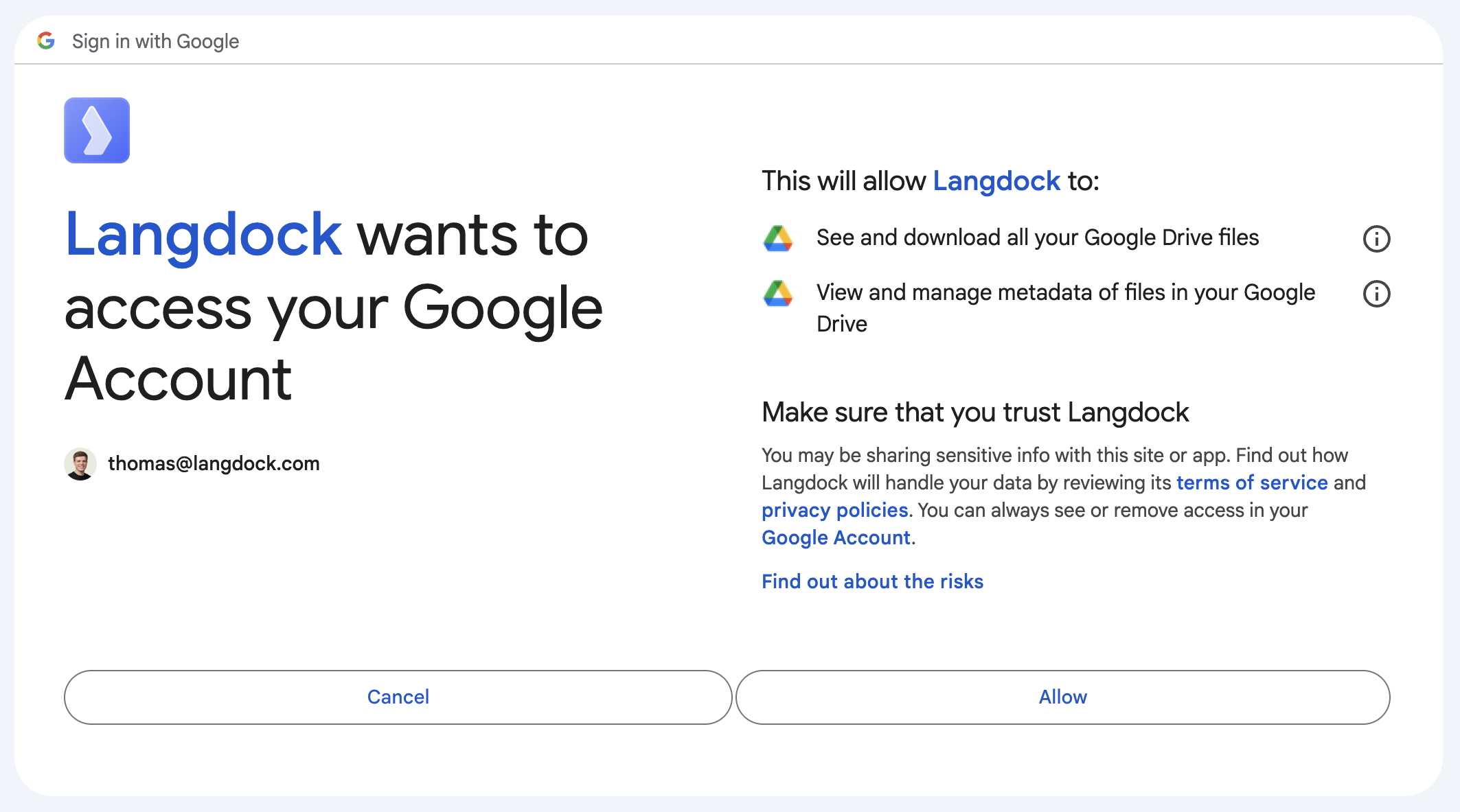
- The integration shows you which data will be shared with Langdock. To process and use your files as your knowledge within Langdock, Langdock needs to see, view and download files. With “Allow”, you are giving consent to share files.
- You are now back in Langdock and can select which files you want to import as knowledge. In our case, we only import the personal drive. With extensive integrations, importing the data completely can take a while. If you want to get started quickly, select only the minimum of files you need.
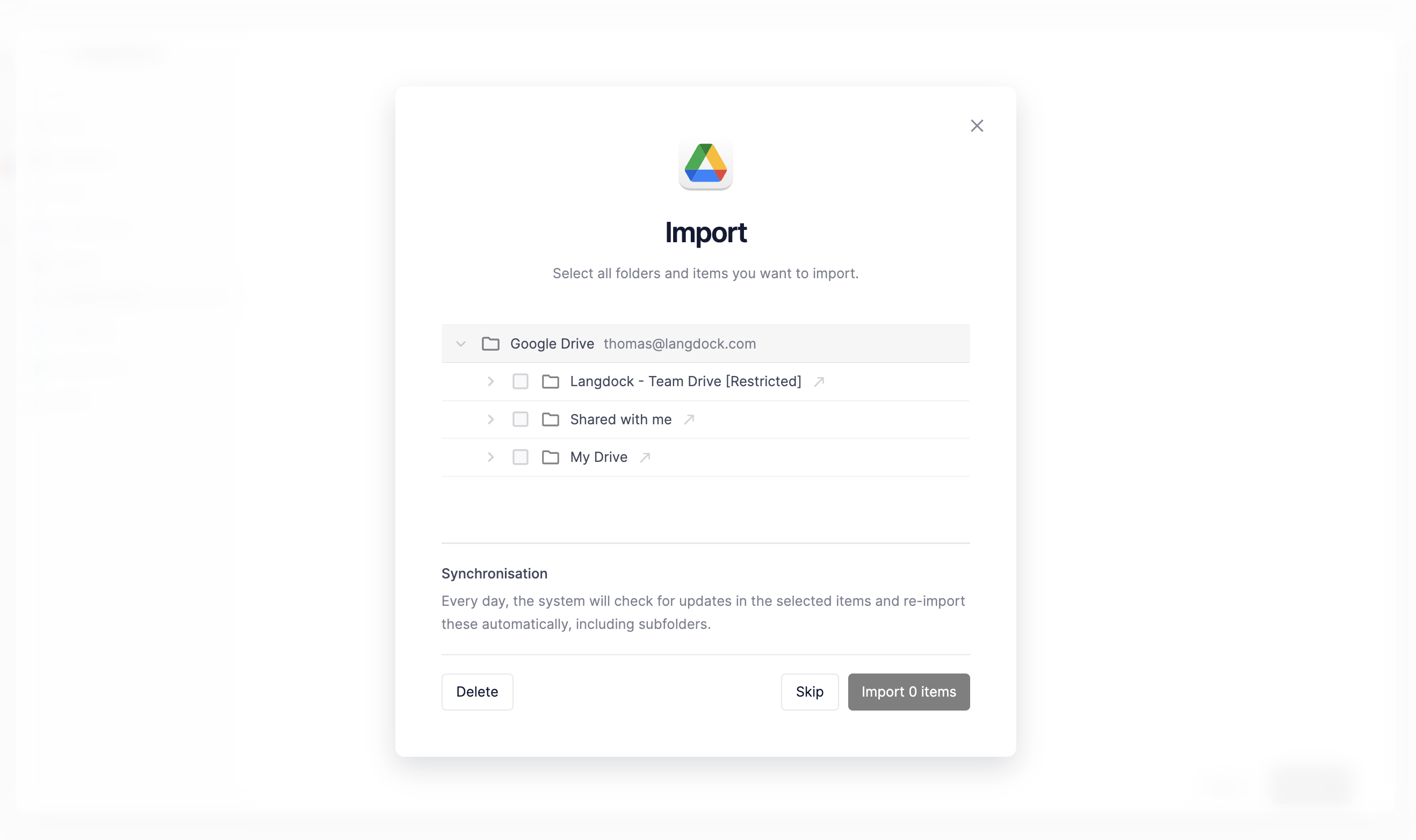
-
Now, the import has started and will run in the background. Now, we have to wait for the integrations to be imported. Press “Ok, understood”.
-
You can now see all the files on Google Drive in a list. Towards the right side, the status of the file is indicated. Once the import is complete, it will change to “Imported.”
Now, you can select the files you want to use as knowledge in your chat or assistant by ticking the box on the left side. Generally, it is advised to select as few sources as possible to provide accurate results.
If you run into any issues or have questions, please reach out to us and we are happy to help: thomas@langdock.com
Was this page helpful?