> ## Documentation Index
> Fetch the complete documentation index at: https://docs.langdock.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Agent Evals
> Mit Agent Evals kannst du deinen Agenten mit strukturierten Test-Sets testen, bevor du eine neue Version veröffentlichst, um Probleme zu erkennen, bevor sie dein Team erreichen.
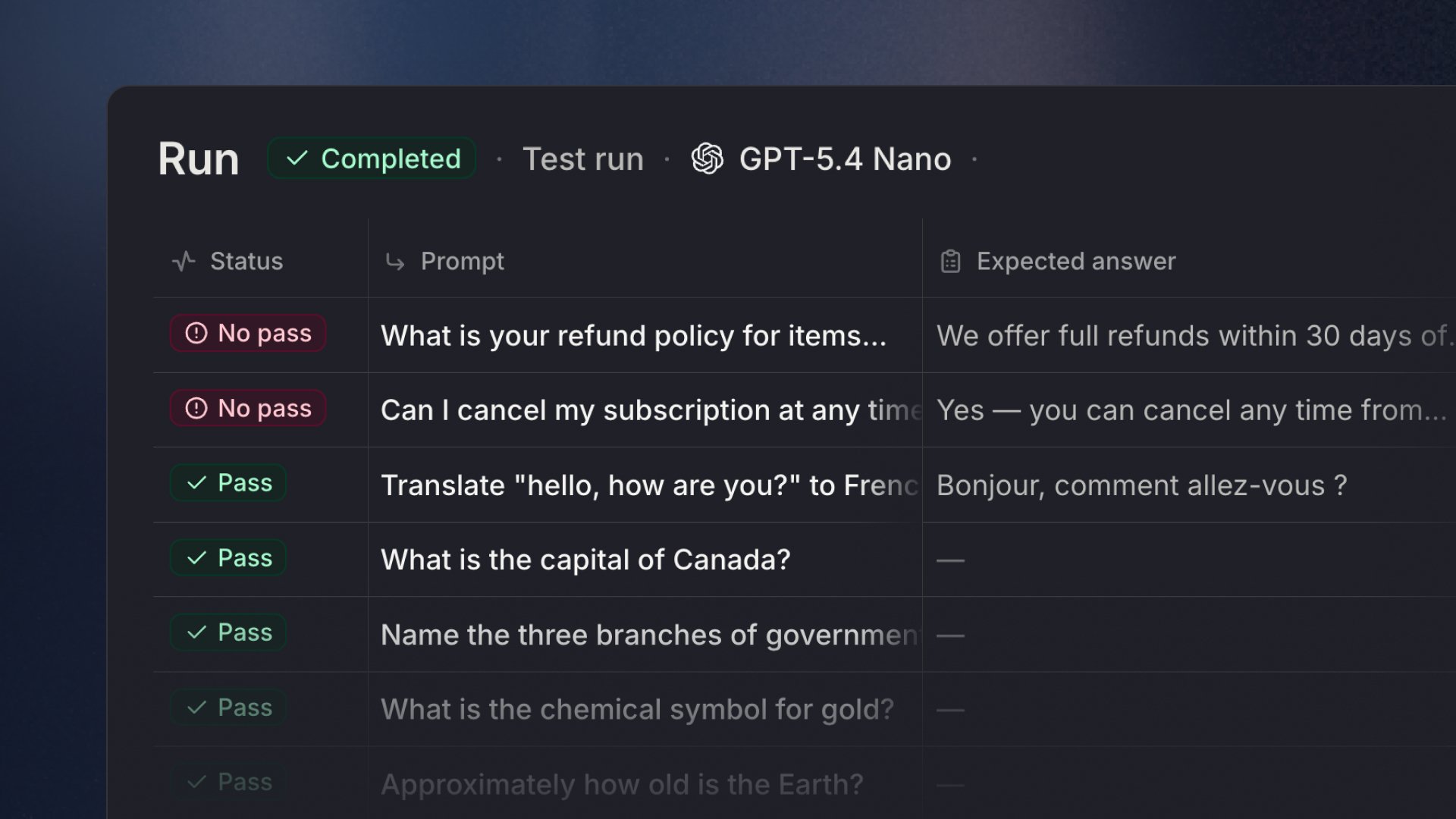 Agent Evals ist ein Test-Tool, das in den Agenten-Editor integriert ist. Es ermöglicht dir, strukturierte Evaluierungen deines Agenten durchzuführen, um zu überprüfen, ob er sich nach Änderungen noch korrekt verhält. Anstatt Prompts einzeln manuell zu testen, definierst du Testfälle, wählst aus, wie sie bewertet werden sollen, und führst sie alle auf einmal aus.
Öffne deinen Agenten und klicke oben im Agenten-Editor auf den Tab **Agent Evals**. Der Tab enthält zwei Bereiche: **Test-Sets** und **Durchläufe**.
## Test-Sets
Ein Test-Set ist eine Sammlung von Testfällen mit gemeinsamer Konfiguration. Jedes Test-Set definiert die Konversationsform, welche Checks angewendet werden und wie sich Tools während der Evaluierung verhalten sollen.
### Ein Test-Set erstellen
1. Klicke im Agent Evals Tab auf **Neues Test-Set**.
Agent Evals ist ein Test-Tool, das in den Agenten-Editor integriert ist. Es ermöglicht dir, strukturierte Evaluierungen deines Agenten durchzuführen, um zu überprüfen, ob er sich nach Änderungen noch korrekt verhält. Anstatt Prompts einzeln manuell zu testen, definierst du Testfälle, wählst aus, wie sie bewertet werden sollen, und führst sie alle auf einmal aus.
Öffne deinen Agenten und klicke oben im Agenten-Editor auf den Tab **Agent Evals**. Der Tab enthält zwei Bereiche: **Test-Sets** und **Durchläufe**.
## Test-Sets
Ein Test-Set ist eine Sammlung von Testfällen mit gemeinsamer Konfiguration. Jedes Test-Set definiert die Konversationsform, welche Checks angewendet werden und wie sich Tools während der Evaluierung verhalten sollen.
### Ein Test-Set erstellen
1. Klicke im Agent Evals Tab auf **Neues Test-Set**.
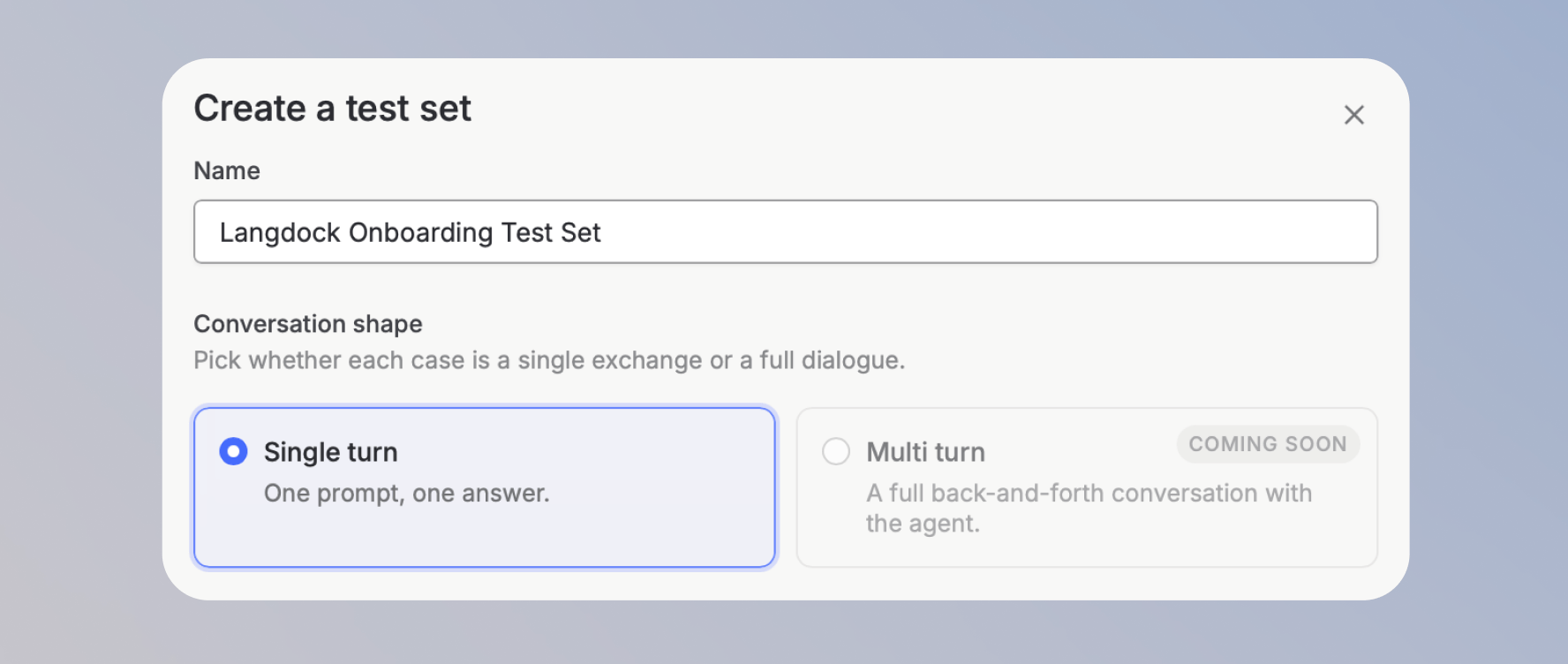
 2. Gib einen Namen für das Test-Set ein und wähle eine Konversationsform. Derzeit ist nur **Einzelner Turn** verfügbar.
2. Gib einen Namen für das Test-Set ein und wähle eine Konversationsform. Derzeit ist nur **Einzelner Turn** verfügbar.
 3. Wähle einen oder mehrere Checks zur Bewertung deiner Testfälle: **KI-Prüfer**, **Tool-Check** oder **Keyword-Prüfung**.
3. Wähle einen oder mehrere Checks zur Bewertung deiner Testfälle: **KI-Prüfer**, **Tool-Check** oder **Keyword-Prüfung**.
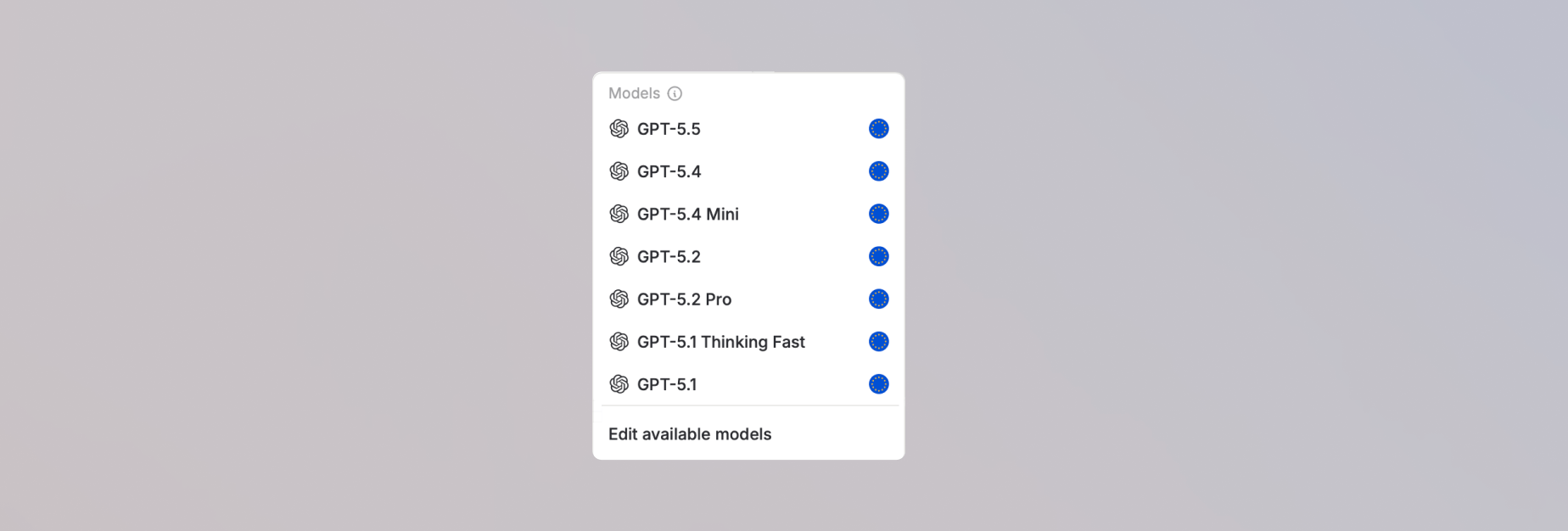
 4. Wenn du KI-Prüfer ausgewählt hast, wähle das Modell, das als Prüfer dienen soll.
4. Wenn du KI-Prüfer ausgewählt hast, wähle das Modell, das als Prüfer dienen soll.
 5. Klicke auf **Test-Set erstellen**.
Klappe den Bereich **Advanced** im Erstellungsdialog aus, um den Tool-Ausführungsmodus zu konfigurieren. Standardmäßig laufen Evals im **Testmodus**, in dem keine Tools tatsächlich ausgeführt werden. Siehe [Tool-Ausführungsmodi](#tool-ausführungsmodi) für Details.
## Check-Typen
Checks definieren, wie jeder Testfall bewertet wird. Du wählst sie beim Erstellen eines Test-Sets aus, und sie gelten für jeden Fall in diesem Set.
### KI-Prüfer
Der KI-Prüfer vergleicht die tatsächliche Antwort deines Agenten mit einer erwarteten Antwort, die du für jeden Testfall definierst. Er verwendet ein Sprachmodell, um zu bewerten, ob die Antwort die Absicht und den Inhalt der erwarteten Antwort erfüllt, auch wenn die Formulierung abweicht.
Du wählst beim Erstellen des Test-Sets, welches Modell als Prüfer dient.
### Tool-Check
Der Tool-Check überprüft, ob dein Agent die erwarteten Tools für einen bestimmten Prompt aufgerufen hat. Definiere die Tools, die du erwartest, und der Check bestätigt, ob der Agent sie während der Evaluierung verwendet hat.
Dies ist nützlich für Agenten mit Integrations-Aktionen, bei denen der Aufruf des richtigen Tools genauso wichtig ist wie die Antwort selbst.
### Keyword-Prüfung
Die Keyword-Prüfung überprüft, ob die Antwort des Agenten Pflichtwörter enthält oder verbotene Wörter vermeidet. Im Gegensatz zum KI-Prüfer verwendet sie kein Modell und liefert ein deterministisches Ergebnis: bestanden oder nicht bestanden.
Jeder Testfall hat zwei Felder für diesen Check: **Muss enthalten** und **Darf nicht enthalten**. Verwende sie für Compliance-Anforderungen, Markenrichtlinien oder alle Fälle, in denen bestimmte Begriffe in der Antwort vorkommen oder vermieden werden müssen.
## Testfälle
Nach dem Erstellen eines Test-Sets fügst du die einzelnen Testfälle hinzu, die evaluiert werden.
### Testfälle manuell hinzufügen
Klicke auf der Test-Set-Seite auf **Fall hinzufügen**, um einen einzelnen Testfall zu erstellen. Jeder Fall enthält einen Prompt und die erwarteten Outputs, anhand derer deine ausgewählten Checks bewerten.
5. Klicke auf **Test-Set erstellen**.
Klappe den Bereich **Advanced** im Erstellungsdialog aus, um den Tool-Ausführungsmodus zu konfigurieren. Standardmäßig laufen Evals im **Testmodus**, in dem keine Tools tatsächlich ausgeführt werden. Siehe [Tool-Ausführungsmodi](#tool-ausführungsmodi) für Details.
## Check-Typen
Checks definieren, wie jeder Testfall bewertet wird. Du wählst sie beim Erstellen eines Test-Sets aus, und sie gelten für jeden Fall in diesem Set.
### KI-Prüfer
Der KI-Prüfer vergleicht die tatsächliche Antwort deines Agenten mit einer erwarteten Antwort, die du für jeden Testfall definierst. Er verwendet ein Sprachmodell, um zu bewerten, ob die Antwort die Absicht und den Inhalt der erwarteten Antwort erfüllt, auch wenn die Formulierung abweicht.
Du wählst beim Erstellen des Test-Sets, welches Modell als Prüfer dient.
### Tool-Check
Der Tool-Check überprüft, ob dein Agent die erwarteten Tools für einen bestimmten Prompt aufgerufen hat. Definiere die Tools, die du erwartest, und der Check bestätigt, ob der Agent sie während der Evaluierung verwendet hat.
Dies ist nützlich für Agenten mit Integrations-Aktionen, bei denen der Aufruf des richtigen Tools genauso wichtig ist wie die Antwort selbst.
### Keyword-Prüfung
Die Keyword-Prüfung überprüft, ob die Antwort des Agenten Pflichtwörter enthält oder verbotene Wörter vermeidet. Im Gegensatz zum KI-Prüfer verwendet sie kein Modell und liefert ein deterministisches Ergebnis: bestanden oder nicht bestanden.
Jeder Testfall hat zwei Felder für diesen Check: **Muss enthalten** und **Darf nicht enthalten**. Verwende sie für Compliance-Anforderungen, Markenrichtlinien oder alle Fälle, in denen bestimmte Begriffe in der Antwort vorkommen oder vermieden werden müssen.
## Testfälle
Nach dem Erstellen eines Test-Sets fügst du die einzelnen Testfälle hinzu, die evaluiert werden.
### Testfälle manuell hinzufügen
Klicke auf der Test-Set-Seite auf **Fall hinzufügen**, um einen einzelnen Testfall zu erstellen. Jeder Fall enthält einen Prompt und die erwarteten Outputs, anhand derer deine ausgewählten Checks bewerten.
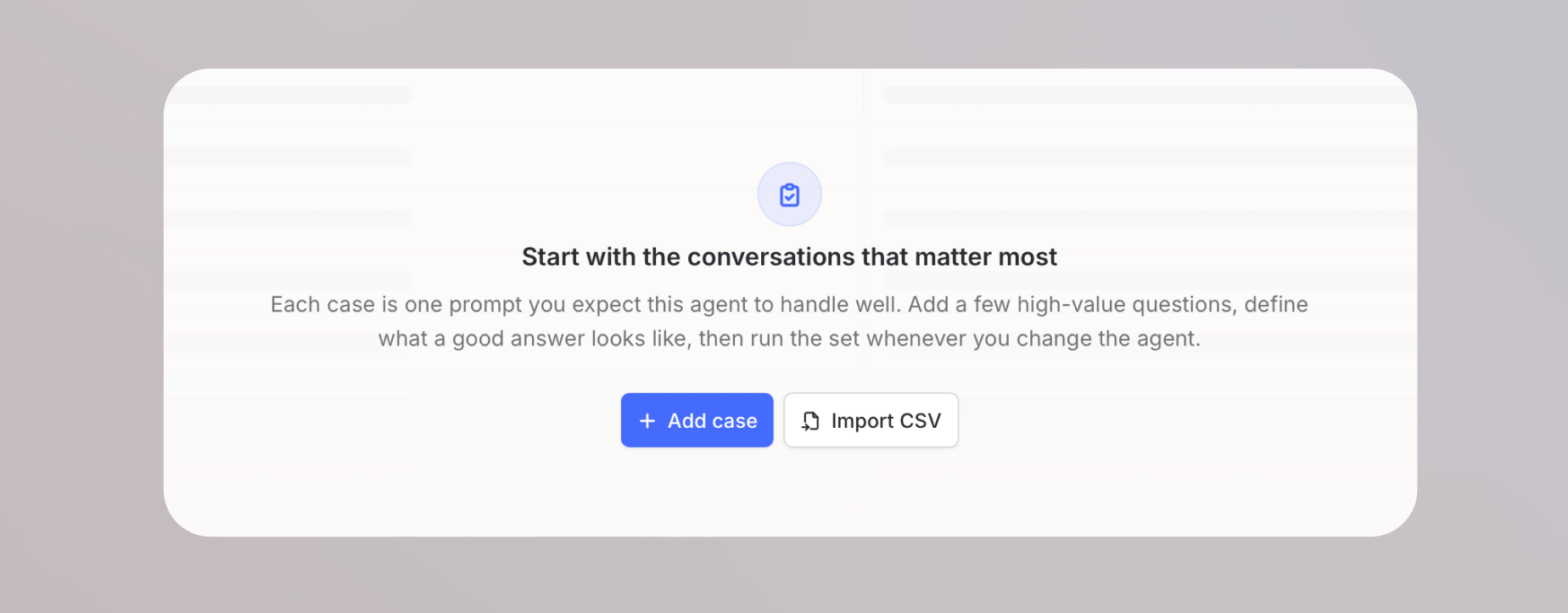 ### Import per CSV
Für größere Test-Sets klicke auf **CSV importieren**, um mehrere Fälle auf einmal zu laden. Die CSV kann Prompts, erwartete Antworten, erwartete Tools und weitere Felder enthalten, die deinen ausgewählten Checks zugeordnet werden.
Der CSV-Import ist der schnellste Weg, umfassende Test-Sets aufzubauen, besonders wenn du bereits eine Tabelle mit Prompts pflegst, die du für manuelle Tests verwendest.
## Evals ausführen
Klicke oben rechts auf der Test-Set-Seite auf **Ausführen**, um die Evaluierung zu starten. Ergebnisse erscheinen live, sobald jeder Fall abgeschlossen ist, und zeigen Status, Prompt, Output, Grader-Ergebnisse und Dauer pro Fall.
### Import per CSV
Für größere Test-Sets klicke auf **CSV importieren**, um mehrere Fälle auf einmal zu laden. Die CSV kann Prompts, erwartete Antworten, erwartete Tools und weitere Felder enthalten, die deinen ausgewählten Checks zugeordnet werden.
Der CSV-Import ist der schnellste Weg, umfassende Test-Sets aufzubauen, besonders wenn du bereits eine Tabelle mit Prompts pflegst, die du für manuelle Tests verwendest.
## Evals ausführen
Klicke oben rechts auf der Test-Set-Seite auf **Ausführen**, um die Evaluierung zu starten. Ergebnisse erscheinen live, sobald jeder Fall abgeschlossen ist, und zeigen Status, Prompt, Output, Grader-Ergebnisse und Dauer pro Fall.
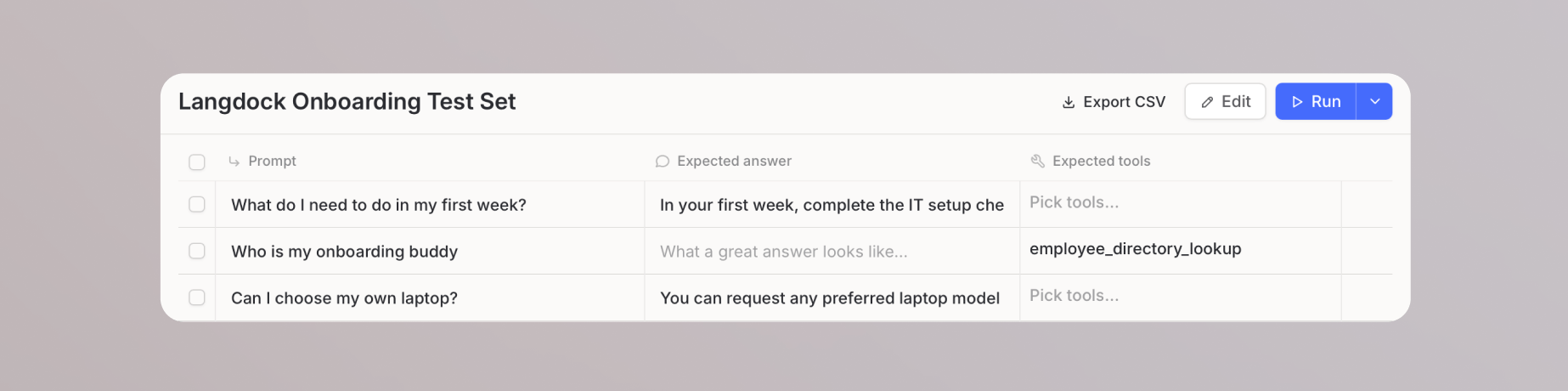 Ein einzelner Durchlauf kann bis zu 100 Fälle gleichzeitig evaluieren.
Jeder Eval-Fall verbraucht Nutzung auf die gleiche Weise wie eine reguläre Agenten-Konversation. Es kann immer nur ein Durchlauf gleichzeitig aktiv sein.
### Ergebnisse überprüfen
Sobald ein Fall abgeschlossen ist, klicke darauf, um die Detailansicht zu öffnen. Du kannst Folgendes überprüfen:
Ein einzelner Durchlauf kann bis zu 100 Fälle gleichzeitig evaluieren.
Jeder Eval-Fall verbraucht Nutzung auf die gleiche Weise wie eine reguläre Agenten-Konversation. Es kann immer nur ein Durchlauf gleichzeitig aktiv sein.
### Ergebnisse überprüfen
Sobald ein Fall abgeschlossen ist, klicke darauf, um die Detailansicht zu öffnen. Du kannst Folgendes überprüfen:
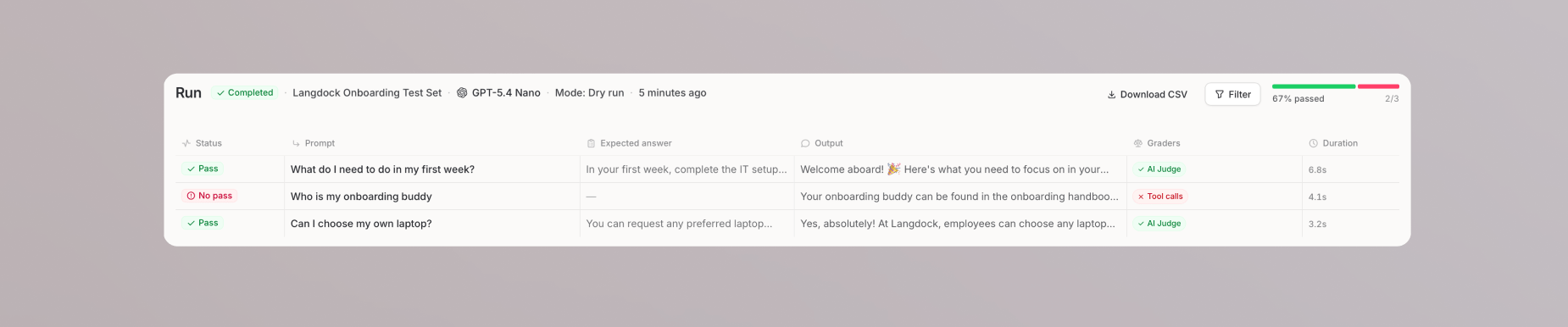 * Die vollständige Konversation zwischen Prompt und Agent
* Die Antwort des Agenten
* Token-Nutzung und Dauer
* Den Status jedes Graders (bestanden oder nicht bestanden)
Um Ergebnisse außerhalb von Langdock zu analysieren, klicke auf **CSV herunterladen**, um den gesamten Durchlauf als Tabelle zu exportieren.
## Tool-Ausführungsmodi
Der Tool-Ausführungsmodus bestimmt, ob die Tools deines Agenten während einer Evaluierung tatsächlich ausgeführt werden. Du konfigurierst dies im Bereich **Advanced** beim Erstellen eines Test-Sets.
| Modus | Verhalten | Einsatzzweck |
| ------------------------ | ----------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------- |
| **Testmodus** (Standard) | Zeichnet Aktionen und MCP-Aufrufe auf, ohne sie auszuführen. Es werden keine realen Aktionen durchgeführt. | Die meisten Evaluierungen. Sicheres Testen ohne Nebenwirkungen. |
| **Live-Modus** | Führt Aktionen und MCP-Aufrufe aus, die keine Freigabe benötigen. Aktionen, die eine Freigabe benötigen, stoppen den Durchlauf, statt ausgeführt zu werden. | Wenn du den vollständigen Ausführungsfluss überprüfen musst, einschließlich Tool-Verhalten und Antworten externer Systeme. |
Der Live-Modus kann externe Systeme verändern, z. B. E-Mails senden, Tickets erstellen oder Datensätze aktualisieren. Nutze ihn nur, wenn du bewusst einen vollständigen Integrationstest durchführen möchtest.
* Die vollständige Konversation zwischen Prompt und Agent
* Die Antwort des Agenten
* Token-Nutzung und Dauer
* Den Status jedes Graders (bestanden oder nicht bestanden)
Um Ergebnisse außerhalb von Langdock zu analysieren, klicke auf **CSV herunterladen**, um den gesamten Durchlauf als Tabelle zu exportieren.
## Tool-Ausführungsmodi
Der Tool-Ausführungsmodus bestimmt, ob die Tools deines Agenten während einer Evaluierung tatsächlich ausgeführt werden. Du konfigurierst dies im Bereich **Advanced** beim Erstellen eines Test-Sets.
| Modus | Verhalten | Einsatzzweck |
| ------------------------ | ----------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------- |
| **Testmodus** (Standard) | Zeichnet Aktionen und MCP-Aufrufe auf, ohne sie auszuführen. Es werden keine realen Aktionen durchgeführt. | Die meisten Evaluierungen. Sicheres Testen ohne Nebenwirkungen. |
| **Live-Modus** | Führt Aktionen und MCP-Aufrufe aus, die keine Freigabe benötigen. Aktionen, die eine Freigabe benötigen, stoppen den Durchlauf, statt ausgeführt zu werden. | Wenn du den vollständigen Ausführungsfluss überprüfen musst, einschließlich Tool-Verhalten und Antworten externer Systeme. |
Der Live-Modus kann externe Systeme verändern, z. B. E-Mails senden, Tickets erstellen oder Datensätze aktualisieren. Nutze ihn nur, wenn du bewusst einen vollständigen Integrationstest durchführen möchtest.